## Diagram: Transformer Model Text Generation Process
### Overview
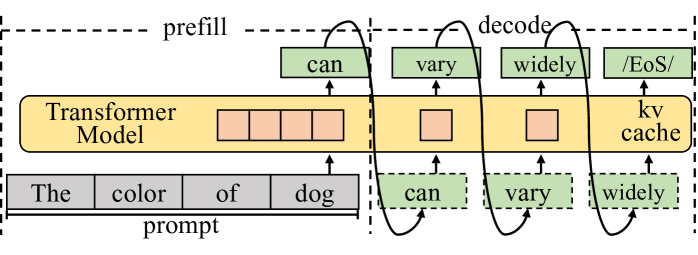
The diagram illustrates the workflow of a Transformer Model during text generation, highlighting the **prefill** and **decode** phases. It shows how input prompts are processed to generate output text, with attention to the **kv cache** and sequence of generated words.
### Components/Axes
1. **Transformer Model**: Central block with four orange squares representing attention/processing layers.
2. **Prompt**: Input text "The color of dog" at the bottom, feeding into the model.
3. **Prefill Phase**: Arrows from the prompt to the Transformer Model, indicating initial input processing.
4. **Decode Phase**: Arrows from the Transformer Model to green boxes labeled "can", "vary", "widely", and "/EoS/", representing generated output tokens.
5. **kv Cache**: Labeled on the right side of the Transformer Model, storing key-value pairs for efficient decoding.
6. **EoS Marker**: "/EoS/" (End of Sentence) token indicating completion of text generation.
### Detailed Analysis
- **Prefill**: The prompt "The color of dog" is processed by the Transformer Model to initialize hidden states.
- **Decode**: The model generates tokens sequentially:
- "can" → "vary" → "widely" → "/EoS/".
- **kv Cache**: Positioned to the right of the Transformer Model, it stores intermediate key-value pairs to accelerate autoregressive decoding.
- **Token Flow**: Arrows show the sequence of generated words, with dashed lines indicating attention mechanisms or positional relationships.
### Key Observations
- The model generates text in a left-to-right sequence, with each token depending on prior context.
- The "/EoS/" token marks the end of the generated sequence, terminating the decoding process.
- The kv cache is critical for reducing computational redundancy during token generation.
### Interpretation
This diagram demonstrates how Transformer Models balance **prefilling** (initial input processing) and **decoding** (autoregressive text generation). The kv cache optimizes efficiency by reusing computed key-value pairs, avoiding redundant calculations. The sequence "can vary widely" suggests the model’s ability to generate contextually coherent phrases, while "/EoS/" ensures termination. The absence of numerical data implies this is a conceptual workflow rather than a performance metric visualization.