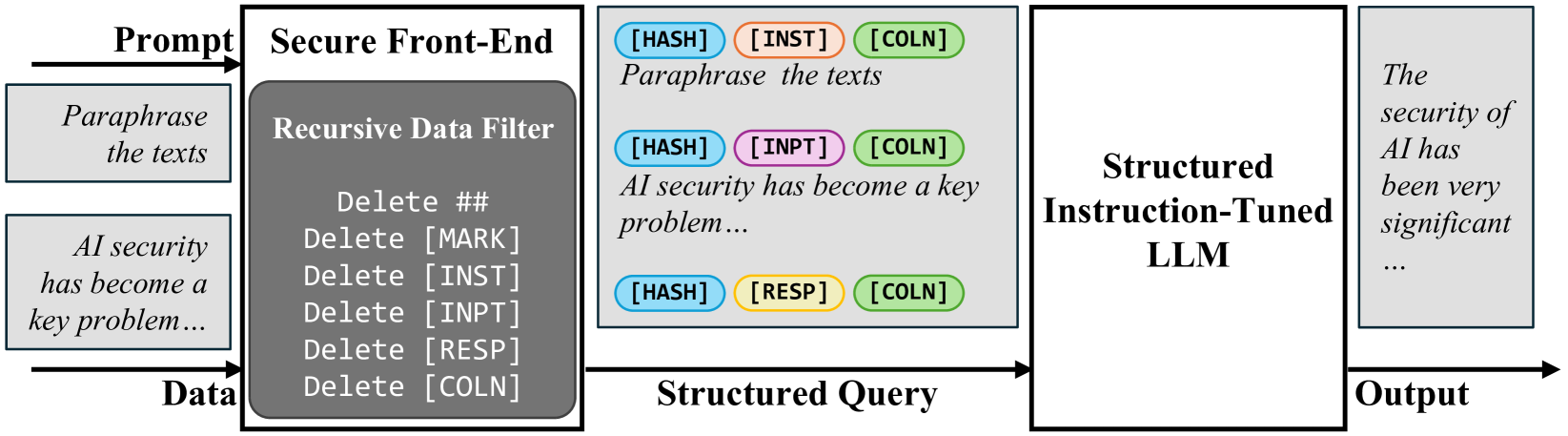
## System Diagram: Secure Data Processing Pipeline for LLMs
### Overview
The image is a technical flowchart illustrating a secure data processing pipeline designed to sanitize and structure user inputs before they are processed by a Large Language Model (LLM). The system focuses on removing potentially sensitive or problematic formatting markers and restructuring the data into a query format. The overall flow moves from left to right: raw inputs are filtered, structured, processed by an LLM, and produce a final output.
### Components/Axes
The diagram is composed of five main rectangular blocks connected by directional arrows, indicating data flow.
1. **Input Section (Leftmost):**
* Two input boxes are shown, labeled with arrows as "Prompt" and "Data".
* **Prompt Box:** Contains the text "Paraphrase the texts".
* **Data Box:** Contains the text "AI security has become a key problem...".
2. **Secure Front-End (First Processing Block):**
* A large rectangle labeled "Secure Front-End".
* Inside, a darker gray sub-block is labeled "Recursive Data Filter".
* The filter lists the following deletion operations:
* `Delete ##`
* `Delete [MARK]`
* `Delete [INST]`
* `Delete [INPT]`
* `Delete [RESP]`
* `Delete [COLN]`
3. **Structured Query (Middle Block):**
* A large rectangle containing three rows of processed data.
* Each row consists of colored oval tags followed by example text.
* **Row 1:** Blue `[HASH]` tag, Orange `[INST]` tag, Green `[COLN]` tag. Text: "Paraphrase the texts".
* **Row 2:** Blue `[HASH]` tag, Pink `[INPT]` tag, Green `[COLN]` tag. Text: "AI security has become a key problem...".
* **Row 3:** Blue `[HASH]` tag, Yellow `[RESP]` tag, Green `[COLN]` tag. (No accompanying text is shown for this row).
* An arrow labeled "Structured Query" points from this block to the next.
4. **Structured Instruction-Tuned LLM (Processing Block):**
* A large, empty rectangle labeled "Structured Instruction-Tuned LLM". This represents the core AI model.
5. **Output (Rightmost Block):**
* A rectangle labeled "Output".
* Contains the text: "The security of AI has been very significant...".
### Detailed Analysis
* **Data Flow & Transformation:**
1. The system accepts two parallel inputs: a command ("Prompt") and associated content ("Data").
2. Both inputs pass through the "Recursive Data Filter" within the "Secure Front-End". This filter systematically removes specific formatting markers (`##`, `[MARK]`, `[INST]`, `[INPT]`, `[RESP]`, `[COLN]`).
3. The filtered data is then reorganized into a "Structured Query". This structure appears to tag different components of the original input:
* `[HASH]` (Blue): Likely a unique identifier or hash for the data segment.
* `[INST]` (Orange) / `[INPT]` (Pink) / `[RESP]` (Yellow): Seem to categorize the type of data (Instruction, Input, Response).
* `[COLN]` (Green): Possibly a delimiter or marker for a colon, indicating the start of the content.
4. This structured query is fed into the "Structured Instruction-Tuned LLM".
5. The LLM produces a final "Output", which is a paraphrased or processed version of the original input data.
* **Color-Coding of Tags:**
* **Blue (`[HASH]`):** Consistent across all three rows in the Structured Query.
* **Orange (`[INST]`):** Used for the prompt/command row.
* **Pink (`[INPT]`):** Used for the data/content row.
* **Yellow (`[RESP]`):** Used for a third, empty row, possibly reserved for the model's response within the query structure.
* **Green (`[COLN]`):** Consistent across all three rows.
### Key Observations
1. **Security Focus:** The primary function of the initial "Secure Front-End" and its "Recursive Data Filter" is to strip out specific syntactic markers. This suggests a security or sanitization layer designed to prevent prompt injection or manipulation via these special tokens.
2. **Structured Input Format:** The system does not feed raw text to the LLM. Instead, it enforces a structured format where different parts of the interaction (instruction, input, response slot) are explicitly tagged and labeled.
3. **Paraphrasing Task:** The example used throughout the pipeline is a paraphrasing task ("Paraphrase the texts" -> "The security of AI has been very significant..."). This demonstrates the pipeline's end-to-end functionality.
4. **Asymmetric Data:** The "Structured Query" block shows three rows, but only two have corresponding example text. The third row, tagged `[RESP]`, is empty, indicating it is a placeholder for the model's generated response within the structured format.
### Interpretation
This diagram depicts a **preprocessing and security architecture for LLM interactions**. Its core purpose is to create a controlled, sanitized environment for user inputs.
* **The Problem it Solves:** LLMs can be vulnerable to "prompt injection," where malicious users embed special commands (like `[INST]` or `##`) within their data to hijack the model's behavior. This pipeline mitigates that risk by first deleting all such markers.
* **The Solution's Logic:** After sanitization, the system rebuilds the user's intent into a rigid, machine-readable structure. By tagging the instruction, input, and response areas explicitly, it ensures the LLM interprets the data in the intended context, further reducing ambiguity and attack surface.
* **Implication:** This represents a move towards more secure and reliable LLM deployment, especially in applications where user inputs are untrusted. The "Structured Instruction-Tuned LLM" on the right is presumably trained to understand this specific tagged format, making the entire system a cohesive, security-aware unit. The output is a clean, processed result derived from the original, now-secured input.