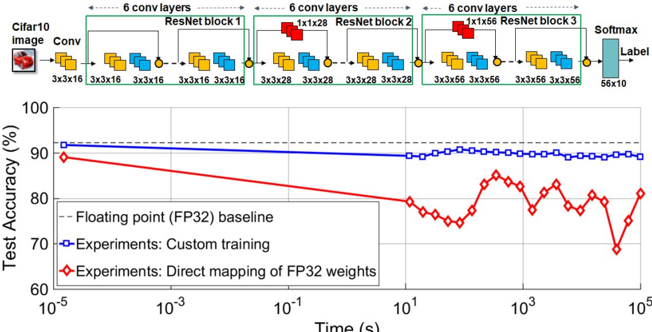
## Neural Network Architecture and Performance Chart
### Overview
The image presents a diagram of a convolutional neural network (CNN) architecture, followed by a chart comparing the test accuracy of different training methods over time. The CNN architecture consists of convolutional layers and ResNet blocks, while the chart compares the performance of a floating-point baseline, custom training, and direct mapping of FP32 weights.
### Components/Axes
**Top: CNN Architecture Diagram**
* **Header:** "6 conv layers" is repeated above each ResNet block.
* **Input:** "Cifar10 image" followed by "Conv" block.
* The input image is represented by a small image of a red car.
* The "Conv" block has dimensions "3x3x16".
* **ResNet Blocks:** There are three ResNet blocks labeled "ResNet block 1", "ResNet block 2", and "ResNet block 3".
* ResNet block 1: Contains convolutional layers with dimensions "3x3x16".
* ResNet block 2: Contains convolutional layers with dimensions "3x3x28" and a "1x1x28" layer.
* ResNet block 3: Contains convolutional layers with dimensions "3x3x56" and a "1x1x56" layer.
* **Output:** "Softmax" layer with dimensions "56x10" leading to "Label".
* **Connections:** Blocks are connected by arrows indicating the flow of data. Small yellow circles are present at the end of each block.
**Bottom: Test Accuracy Chart**
* **Y-axis:** "Test Accuracy (%)", ranging from 60 to 100. Markers at 70, 80, 90, and 100.
* **X-axis:** "Time (s)" on a logarithmic scale, ranging from 10<sup>-5</sup> to 10<sup>5</sup>. Markers at 10<sup>-5</sup>, 10<sup>-3</sup>, 10<sup>-1</sup>, 10<sup>1</sup>, 10<sup>3</sup>, and 10<sup>5</sup>.
* **Legend (bottom-left):**
* "-- Floating point (FP32) baseline" (dashed black line)
* "Experiments: Custom training" (solid blue line with square markers)
* "Experiments: Direct mapping of FP32 weights" (solid red line with diamond markers)
### Detailed Analysis
**CNN Architecture:**
* The network processes a Cifar10 image through an initial convolutional layer.
* The image then passes through three ResNet blocks, each containing multiple convolutional layers.
* The dimensions of the convolutional layers increase through the network (16 -> 28 -> 56).
* The output of the final ResNet block is fed into a Softmax layer to produce a label.
**Test Accuracy Chart:**
* **Floating point (FP32) baseline (dashed black line):** The baseline accuracy is approximately constant at 92%.
* **Experiments: Custom training (solid blue line with square markers):** The accuracy starts at approximately 90% at 10<sup>-5</sup> seconds, decreases slightly to approximately 89% at 10<sup>1</sup> seconds, and then remains relatively stable around 89-90% until 10<sup>5</sup> seconds.
* **Experiments: Direct mapping of FP32 weights (solid red line with diamond markers):** The accuracy starts at approximately 89% at 10<sup>-5</sup> seconds, decreases to approximately 75% at 10<sup>1</sup> seconds, and then fluctuates between 75% and 85% from 10<sup>1</sup> to 10<sup>5</sup> seconds.
### Key Observations
* The custom training method (blue line) maintains a relatively stable accuracy over time, close to the FP32 baseline.
* The direct mapping of FP32 weights (red line) initially performs similarly to the custom training, but its accuracy degrades significantly over time and exhibits more fluctuation.
* The x-axis is logarithmic, indicating that the performance is being evaluated over a wide range of time scales.
### Interpretation
The data suggests that custom training is a more effective approach than direct mapping of FP32 weights for maintaining accuracy over time. The direct mapping method may suffer from issues related to weight quantization or adaptation, leading to the observed performance degradation and fluctuations. The FP32 baseline provides a benchmark for the maximum achievable accuracy, and the custom training method comes close to achieving this level of performance. The chart highlights the importance of proper training techniques when dealing with different weight representations or hardware constraints.