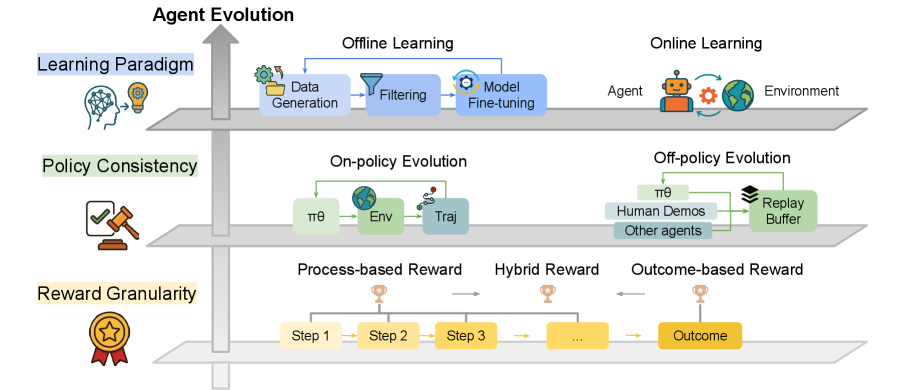
## Agent Evolution Diagram
### Overview
The image is a diagram illustrating the evolution of agents in reinforcement learning across three key dimensions: learning paradigm, policy consistency, and reward granularity. It depicts different approaches to agent learning, policy evolution, and reward design, organized in a layered structure.
### Components/Axes
* **Overall Title:** Agent Evolution
* **Vertical Axis (Implied):** Agent Evolution (indicated by an upward-pointing arrow)
* **Level 1:** Learning Paradigm
* Offline Learning: Data Generation -> Filtering -> Model Fine-tuning
* Online Learning: Agent -> Environment
* **Level 2:** Policy Consistency
* On-policy Evolution: πθ -> Env -> Traj
* Off-policy Evolution: πθ, Human Demos, Other agents -> Replay Buffer
* **Level 3:** Reward Granularity
* Process-based Reward: Step 1 -> Step 2 -> Step 3
* Hybrid Reward: Indicated by "..."
* Outcome-based Reward: Outcome
### Detailed Analysis or ### Content Details
**Level 1: Learning Paradigm**
* **Offline Learning:**
* Data Generation: A block labeled "Data Generation" with an icon of gears and a document.
* Filtering: A block labeled "Filtering" with a filter icon.
* Model Fine-tuning: A block labeled "Model Fine-tuning" with an icon of gears.
* Flow: Data Generation -> Filtering -> Model Fine-tuning. A curved arrow goes from "Model Fine-tuning" back to "Data Generation".
* **Online Learning:**
* Agent: A block labeled "Agent" with a robot icon.
* Environment: A block labeled "Environment" with a globe icon.
* Flow: Agent interacts with the Environment.
**Level 2: Policy Consistency**
* **On-policy Evolution:**
* πθ: A block labeled "πθ".
* Env: A block labeled "Env" with a globe icon.
* Traj: A block labeled "Traj" with a trajectory icon.
* Flow: πθ -> Env -> Traj. A curved arrow goes from "Traj" back to "πθ".
* **Off-policy Evolution:**
* πθ: A block labeled "πθ".
* Human Demos: A block labeled "Human Demos".
* Other agents: A block labeled "Other agents".
* Replay Buffer: A block labeled "Replay Buffer" with a stack icon.
* Flow: πθ, Human Demos, and Other agents -> Replay Buffer. A curved arrow goes from "Replay Buffer" back to "πθ".
**Level 3: Reward Granularity**
* **Process-based Reward:**
* Step 1: A block labeled "Step 1".
* Step 2: A block labeled "Step 2".
* Step 3: A block labeled "Step 3".
* Flow: Step 1 -> Step 2 -> Step 3.
* **Hybrid Reward:**
* Indicated by "..."
* **Outcome-based Reward:**
* Outcome: A block labeled "Outcome".
### Key Observations
* The diagram presents a layered approach to agent evolution, considering different aspects of the learning process.
* Each level represents a different design choice in reinforcement learning.
* The arrows indicate the flow of data or interaction between components.
### Interpretation
The diagram illustrates the design space for reinforcement learning agents. It highlights the trade-offs and options available when designing an agent, from the learning paradigm (offline vs. online) to the policy consistency (on-policy vs. off-policy) and the reward granularity (process-based vs. outcome-based). The diagram suggests that agent evolution involves making choices along these dimensions to create an effective learning system. The cyclical arrows in the On-policy and Off-policy Evolution sections indicate iterative learning processes.