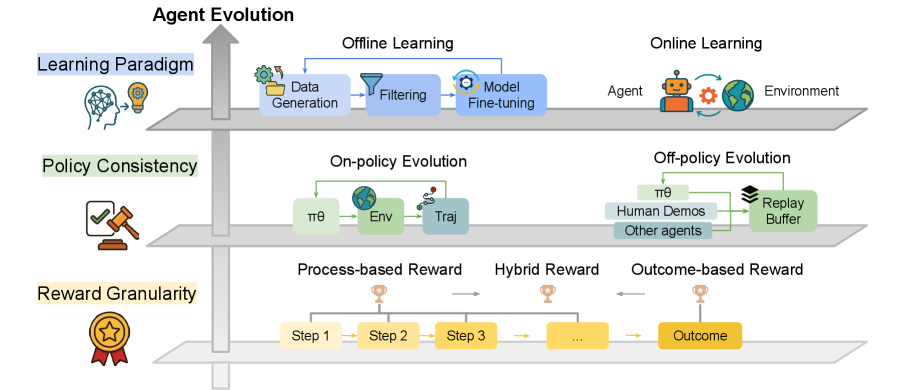
## Diagram: Agent Evolution
### Overview
This is a conceptual diagram illustrating three key dimensions of evolution in artificial intelligence agents. The diagram is structured as three horizontal layers, each representing a distinct aspect of agent development, connected by a central vertical arrow labeled "Agent Evolution" pointing upward, indicating progression or hierarchy. The overall aesthetic is clean and technical, using simple icons and color-coded boxes to represent different concepts and processes.
### Components/Axes
The diagram is divided into three primary horizontal sections, each with a title on the left accompanied by an icon:
1. **Top Layer: Learning Paradigm** (Icon: A brain with a lightbulb)
2. **Middle Layer: Policy Consistency** (Icon: A gavel over a document with a checkmark)
3. **Bottom Layer: Reward Granularity** (Icon: A medal with a star)
A large, gray, upward-pointing arrow runs vertically through the left side of all three layers, labeled at the top with the main title: **"Agent Evolution"**.
### Detailed Analysis
#### **1. Learning Paradigm (Top Layer)**
This layer contrasts two fundamental approaches to how an agent learns.
* **Left Side: Offline Learning**
* A blue box labeled **"Data Generation"** (icon: gears and a folder) points to a funnel icon labeled **"Filtering"**.
* The funnel points to a blue box labeled **"Model Fine-tuning"** (icon: a gear).
* A blue arrow loops from "Model Fine-tuning" back to "Data Generation," indicating an iterative cycle.
* **Right Side: Online Learning**
* Depicts a direct interaction loop.
* An orange robot icon labeled **"Agent"** is connected via a circular arrow to a globe icon labeled **"Environment"**.
#### **2. Policy Consistency (Middle Layer)**
This layer details methods for evolving the agent's decision-making policy (πθ).
* **Left Side: On-policy Evolution**
* Shows a direct, sequential flow.
* A green box labeled **"πθ"** (the policy) points to a green box labeled **"Env"** (Environment).
* "Env" points to a blue box labeled **"Traj"** (Trajectory).
* A green arrow loops from "Traj" back to "πθ," indicating the policy is updated using data from its own current interactions.
* **Right Side: Off-policy Evolution**
* Shows a more complex data aggregation process.
* Three sources feed into a central repository:
* A green box labeled **"πθ"** (the current policy).
* A blue box labeled **"Human Demos"** (Human Demonstrations).
* A blue box labeled **"Other agents"**.
* All three point to a green box labeled **"Replay Buffer"** (icon: stacked disks).
* A green arrow loops from the "Replay Buffer" back to "πθ," indicating the policy is updated using stored data from various sources, not just its own current policy.
#### **3. Reward Granularity (Bottom Layer)**
This layer categorizes the types of feedback signals used to train the agent.
* **Left Side: Process-based Reward**
* A series of yellow boxes connected by arrows: **"Step 1"** → **"Step 2"** → **"Step 3"** → **"..."**.
* A small trophy icon is placed above the arrow between "Step 2" and "Step 3," indicating rewards are given for intermediate steps.
* **Center: Hybrid Reward**
* A single yellow box with an ellipsis **"..."**.
* A trophy icon is placed above this box.
* Arrows point to it from both the "Process-based Reward" sequence on the left and the "Outcome-based Reward" on the right, indicating it combines elements of both.
* **Right Side: Outcome-based Reward**
* A single, larger yellow box labeled **"Outcome"**.
* A trophy icon is placed above the arrow leading into this box, indicating reward is given only upon final completion.
### Key Observations
* **Hierarchical Structure:** The vertical "Agent Evolution" arrow suggests that considerations move from foundational learning paradigms, to policy implementation, to the granular design of rewards.
* **Contrasting Pairs:** Each layer presents a clear dichotomy: Offline vs. Online learning, On-policy vs. Off-policy evolution, and Process-based vs. Outcome-based rewards. The "Hybrid Reward" acts as a bridge between the two extremes in the bottom layer.
* **Data Flow Emphasis:** The diagram heavily emphasizes the flow and source of data used for learning, whether it's generated offline, collected online, from the agent's own policy, or from external demonstrations.
* **Iconography:** Simple, universal icons (gears, funnel, globe, robot, gavel, medal, trophy) are used effectively to reinforce the meaning of each text label.
### Interpretation
This diagram provides a structured taxonomy for understanding and designing AI agents, particularly in reinforcement learning or similar fields. It breaks down the complex process of "agent evolution" into three manageable, interrelated dimensions:
1. **Where does the learning data come from?** (Learning Paradigm: Offline vs. Online)
2. **How is the agent's policy updated with respect to the data source?** (Policy Consistency: On-policy vs. Off-policy)
3. **What specific feedback signals guide the learning?** (Reward Granularity: Step-by-step vs. Final outcome)
The relationships show that choices in one layer constrain or inform choices in another. For example, an **Offline Learning** paradigm naturally aligns with an **Off-policy** evolution strategy, as both rely on pre-collected data stored in a buffer. Conversely, **Online Learning** is often paired with **On-policy** methods. The **Reward Granularity** is a cross-cutting concern that applies regardless of the learning paradigm or policy method.
The inclusion of "Hybrid Reward" acknowledges a practical middle ground in complex tasks where both intermediate progress and final success are important. The diagram serves as a conceptual map for researchers or engineers to locate their agent's design choices within a broader landscape of possibilities, highlighting trade-offs between data efficiency, stability, and learning granularity.