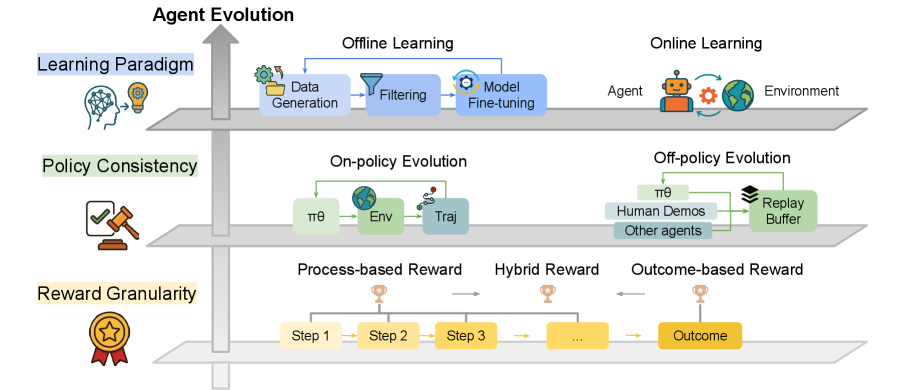
## Diagram: Agent Evolution Framework
### Overview
The diagram illustrates a multi-layered framework for agent evolution, structured into three horizontal layers: **Learning Paradigm**, **Policy Consistency**, and **Reward Granularity**. Each layer contains interconnected components and processes, with directional flow indicated by arrows. The diagram emphasizes the interplay between offline/online learning, policy evolution, and reward structures in shaping agent behavior.
### Components/Axes
1. **Learning Paradigm** (Top Layer):
- **Offline Learning**:
- Data Generation → Filtering → Model Fine-tuning
- **Online Learning**:
- Agent ↔ Environment (cyclical interaction)
2. **Policy Consistency** (Middle Layer):
- **On-policy Evolution**:
- Policy (πθ) → Environment (Env) → Trajectory (Traj)
- **Off-policy Evolution**:
- Human Demos → Replay Buffer → Policy (πθ)
3. **Reward Granularity** (Bottom Layer):
- **Process-based Reward**:
- Step 1 → Step 2 → Step 3 → ... → Outcome
- **Hybrid Reward**:
- Combines process-based and outcome-based rewards (visualized as overlapping trophies).
- **Outcome-based Reward**:
- Directly tied to final outcome (trophy icon).
### Detailed Analysis
- **Offline Learning**:
- Data is generated, filtered, and used to fine-tune models. This suggests a focus on static, pre-collected datasets for initial training.
- **Online Learning**:
- The agent interacts dynamically with the environment, implying real-time learning and adaptation.
- **Policy Consistency**:
- **On-policy**: Policies are updated using trajectories from the current environment.
- **Off-policy**: Policies are updated using human demonstrations and a replay buffer, enabling learning from past experiences.
- **Reward Granularity**:
- Rewards are structured hierarchically:
- **Process-based**: Step-by-step rewards (e.g., intermediate milestones).
- **Hybrid**: Combines process and outcome rewards for balanced feedback.
- **Outcome-based**: Final reward depends solely on the end result.
### Key Observations
1. **Integration of Learning Paradigms**: Offline and online learning are presented as complementary, with offline methods providing foundational knowledge and online methods enabling real-world adaptation.
2. **Policy Evolution Pathways**: On-policy and off-policy methods are distinct but interconnected, with off-policy leveraging human input and replay buffers to mitigate data scarcity.
3. **Reward Structure**: The progression from process-based to outcome-based rewards highlights a shift from granular feedback to holistic evaluation, potentially improving long-term goal alignment.
### Interpretation
The diagram underscores a holistic approach to agent evolution, where:
- **Learning Paradigms** provide the foundation for knowledge acquisition.
- **Policy Consistency** ensures robustness by balancing exploration (online) and exploitation (offline).
- **Reward Granularity** addresses the challenge of sparse rewards by breaking down feedback into manageable steps, while hybrid rewards mitigate the risk of overfitting to short-term outcomes.
The framework suggests that effective agent evolution requires:
1. **Data Quality**: Filtering and fine-tuning in offline learning to avoid noise.
2. **Adaptability**: Online interaction with the environment to handle dynamic scenarios.
3. **Human-in-the-loop**: Off-policy evolution incorporates human expertise to guide learning.
4. **Reward Design**: Hybrid rewards balance immediate feedback with long-term goals, critical for complex tasks.
This structure aligns with principles from reinforcement learning (RL) and human-AI collaboration, emphasizing the need for multi-modal data and adaptive reward systems in advanced AI development.