## Charts: Performance of Language Models
### Overview
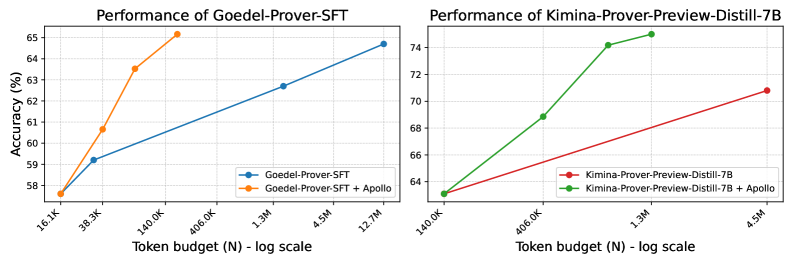
The image presents two line charts comparing the performance (Accuracy in %) of different language models – Goedel-Prover-SFT and Kimina-Prover-Preview-Distill-7B – with and without the addition of Apollo, as a function of token budget (N) on a logarithmic scale.
### Components/Axes
**Chart 1: Performance of Goedel-Prover-SFT**
* **X-axis:** Token budget (N) - log scale. Markers: 16.3K, 39.3K, 140.0K, 406.0K, 1.3M, 4.5M, 12.7M
* **Y-axis:** Accuracy (%) - Scale: 58% to 65%
* **Legend:**
* Blue Line: Goedel-Prover-SFT
* Orange Line: Goedel-Prover-SFT + Apollo
**Chart 2: Performance of Kimina-Prover-Preview-Distill-7B**
* **X-axis:** Token budget (N) - log scale. Markers: 140.0K, 406.0K, 1.3M, 4.5M
* **Y-axis:** Accuracy (%) - Scale: 64% to 74%
* **Legend:**
* Red Line: Kimina-Prover-Preview-Distill-7B
* Green Line: Kimina-Prover-Preview-Distill-7B + Apollo
### Detailed Analysis or Content Details
**Chart 1: Goedel-Prover-SFT**
* **Goedel-Prover-SFT (Blue Line):** The line slopes upward, indicating increasing accuracy with increasing token budget.
* 16.3K: ~58.8%
* 39.3K: ~59.5%
* 140.0K: ~61.5%
* 406.0K: ~62.2%
* 1.3M: ~62.5%
* 4.5M: ~63.5%
* 12.7M: ~64.5%
* **Goedel-Prover-SFT + Apollo (Orange Line):** The line initially rises sharply, then plateaus and decreases slightly.
* 16.3K: ~58.5%
* 39.3K: ~63.5%
* 140.0K: ~64.5%
* 406.0K: ~65.0%
* 1.3M: ~64.0%
* 4.5M: ~63.0%
* 12.7M: ~62.5%
**Chart 2: Kimina-Prover-Preview-Distill-7B**
* **Kimina-Prover-Preview-Distill-7B (Red Line):** The line slopes upward, indicating increasing accuracy with increasing token budget.
* 140.0K: ~64.2%
* 406.0K: ~66.5%
* 1.3M: ~68.5%
* 4.5M: ~69.5%
* **Kimina-Prover-Preview-Distill-7B + Apollo (Green Line):** The line initially rises sharply, then plateaus.
* 140.0K: ~64.5%
* 406.0K: ~68.5%
* 1.3M: ~74.5%
* 4.5M: ~74.0%
### Key Observations
* For Goedel-Prover-SFT, adding Apollo initially improves performance significantly, but the benefit diminishes and even reverses at higher token budgets.
* For Kimina-Prover-Preview-Distill-7B, adding Apollo consistently improves performance, with a significant jump between 406.0K and 1.3M token budgets, and then plateaus.
* Kimina-Prover-Preview-Distill-7B consistently outperforms Goedel-Prover-SFT across all token budgets, even without Apollo.
* The effect of Apollo is more pronounced for lower token budgets.
### Interpretation
The data suggests that the Apollo component is beneficial for both language models, but its effectiveness is dependent on the token budget and the base model. For Goedel-Prover-SFT, Apollo appears to provide a boost in performance at lower token budgets, but becomes detrimental at higher budgets, potentially due to overfitting or other complexities. For Kimina-Prover-Preview-Distill-7B, Apollo consistently improves performance, indicating a more synergistic relationship.
The difference in performance between the two base models suggests that Kimina-Prover-Preview-Distill-7B is inherently more capable, and benefits more from increased token budgets. The plateauing of the green line (Kimina + Apollo) at higher token budgets suggests that the model is reaching its performance limit, and further increasing the token budget does not yield significant improvements.
The logarithmic scale of the x-axis emphasizes the diminishing returns of increasing the token budget. The initial gains in accuracy are more substantial than those achieved at higher token budgets. This suggests that there is a point of diminishing returns where the cost of increasing the token budget outweighs the benefits in terms of accuracy.