## Line Charts: Performance of Goedel-Prover-SFT and Kimina-Prover-Preview-Distill-7B
### Overview
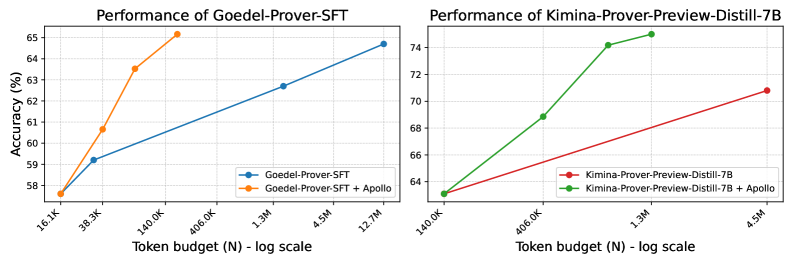
The image contains two side-by-side line charts comparing the accuracy of two AI models (Goedel-Prover-SFT and Kimina-Prover-Preview-Distill-7B) across different token budgets. Each chart includes a baseline model and a variant enhanced with "Apollo." The x-axis uses a logarithmic scale for token budgets, while the y-axis shows accuracy in percentage.
---
### Components/Axes
#### Left Chart: Goedel-Prover-SFT
- **X-axis**: Token budget (N) - log scale
Labels: 16.1K, 38.3K, 140K, 406K, 1.3M, 12.7M
- **Y-axis**: Accuracy (%)
Range: 58% to 65%
- **Legend**:
- Blue line: Goedel-Prover-SFT
- Orange line: Goedel-Prover-SFT + Apollo
#### Right Chart: Kimina-Prover-Preview-Distill-7B
- **X-axis**: Token budget (N) - log scale
Labels: 140K, 406K, 1.3M, 4.5M
- **Y-axis**: Accuracy (%)
Range: 64% to 74%
- **Legend**:
- Red line: Kimina-Prover-Preview-Distill-7B
- Green line: Kimina-Prover-Preview-Distill-7B + Apollo
---
### Detailed Analysis
#### Left Chart: Goedel-Prover-SFT
- **Baseline (Blue)**:
- Starts at **58%** at 16.1K tokens.
- Increases steadily to **64.5%** at 12.7M tokens.
- Slope: Linear upward trend.
- **Apollo-enhanced (Orange)**:
- Starts at **57.5%** at 16.1K tokens.
- Sharp rise to **65.1%** at 406K tokens.
- Plateaus at **64.5%** for larger budgets (1.3M–12.7M).
#### Right Chart: Kimina-Prover-Preview-Distill-7B
- **Baseline (Red)**:
- Starts at **63.5%** at 140K tokens.
- Gradual increase to **70.8%** at 4.5M tokens.
- Slope: Linear upward trend.
- **Apollo-enhanced (Green)**:
- Starts at **63.5%** at 140K tokens.
- Steeper rise to **74.1%** at 1.3M tokens.
- Further improvement to **74.5%** at 4.5M tokens.
---
### Key Observations
1. **Apollo Enhancement**:
- Both models show significant accuracy gains when Apollo is added.
- Larger token budgets amplify these gains, especially in the Kimina model.
2. **Diminishing Returns**:
- Goedel-Prover-SFT + Apollo plateaus at 406K tokens, suggesting limited benefit from further scaling.
3. **Performance Gaps**:
- Kimina-Prover-Preview-Distill-7B + Apollo consistently outperforms its baseline by ~3–4% across all budgets.
- Goedel-Prover-SFT + Apollo outperforms its baseline by ~1–2% at lower budgets but converges at higher budgets.
---
### Interpretation
The data demonstrates that **Apollo significantly boosts model performance**, with the Kimina model benefiting more from scaling. The plateau in Goedel-Prover-SFT + Apollo at 406K tokens implies architectural or optimization limits, whereas Kimina’s continued improvement suggests better scalability. These trends highlight the importance of model architecture and auxiliary components (like Apollo) in achieving high accuracy, particularly at larger token budgets.