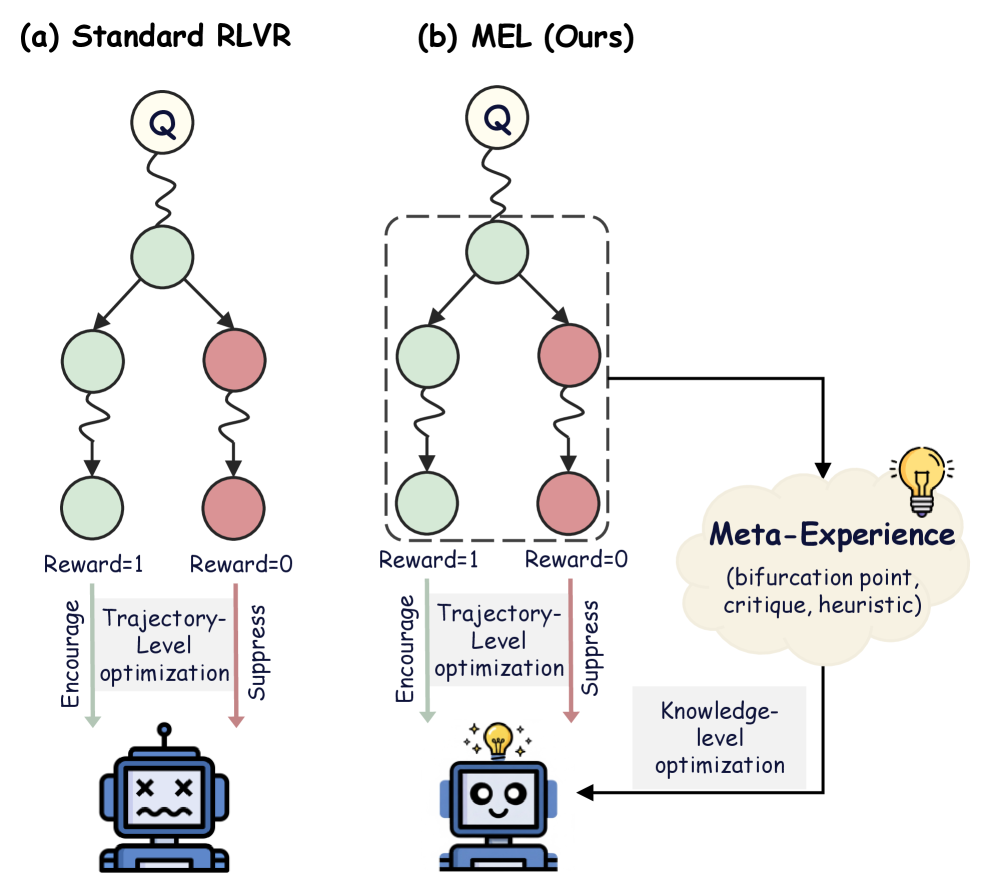
## Diagram: Standard RLVR vs. MEL (Ours)
### Overview
The image presents a comparative diagram illustrating the difference between a "Standard RLVR" approach and a "MEL (Ours)" approach, likely in the context of reinforcement learning. Both diagrams depict a decision tree-like structure, but the MEL approach incorporates a "Meta-Experience" component for knowledge-level optimization.
### Components/Axes
**Diagram (a): Standard RLVR**
* **Title:** (a) Standard RLVR (top-left)
* **Nodes:** A series of interconnected nodes, starting with a node labeled "Q" at the top. The nodes are arranged in a tree-like structure, branching downward. The nodes are colored either light green or light red.
* **Rewards:** "Reward=1" is associated with the left branch, and "Reward=0" is associated with the right branch.
* **Trajectory-Level Optimization:** Text label indicating "Trajectory-Level optimization"
* **Encourage/Suppress:** Arrows pointing downwards, labeled "Encourage" (green arrow) and "Suppress" (red arrow), indicating the effect of the reward on the optimization process.
* **Agent:** A sad-faced robot at the bottom, representing the agent being optimized.
**Diagram (b): MEL (Ours)**
* **Title:** (b) MEL (Ours) (top-right)
* **Nodes:** Similar to the Standard RLVR, with a "Q" node at the top and branching nodes below, colored light green or light red. The nodes are enclosed in a dashed-line box.
* **Rewards:** "Reward=1" is associated with the left branch, and "Reward=0" is associated with the right branch.
* **Trajectory-Level Optimization:** Text label indicating "Trajectory-Level optimization"
* **Encourage/Suppress:** Arrows pointing downwards, labeled "Encourage" (green arrow) and "Suppress" (red arrow), indicating the effect of the reward on the optimization process.
* **Meta-Experience:** A cloud-shaped element on the right, labeled "Meta-Experience" with the subtext "(bifurcation point, critique, heuristic)".
* **Knowledge-Level Optimization:** Text label indicating "Knowledge-level optimization"
* **Agent:** A happy-faced robot with a lightbulb above its head at the bottom, representing the agent being optimized.
### Detailed Analysis
**Diagram (a): Standard RLVR**
* The diagram starts with a "Q" node, which likely represents a state or query.
* The tree branches into two paths. The left path leads to a "Reward=1" node (green), and the right path leads to a "Reward=0" node (red).
* The "Encourage" arrow (green) suggests that a reward of 1 encourages the trajectory-level optimization.
* The "Suppress" arrow (red) suggests that a reward of 0 suppresses the trajectory-level optimization.
* The sad-faced robot indicates a potentially suboptimal outcome.
**Diagram (b): MEL (Ours)**
* The diagram also starts with a "Q" node and branches into two paths with "Reward=1" (green) and "Reward=0" (red) nodes.
* The "Encourage" and "Suppress" arrows function similarly to the Standard RLVR.
* The key difference is the "Meta-Experience" component, which receives input from the decision tree.
* The "Meta-Experience" component then feeds into "Knowledge-level optimization", which in turn influences the agent.
* The happy-faced robot with a lightbulb suggests an improved outcome due to the incorporation of meta-experience.
### Key Observations
* The primary difference between the two approaches is the addition of the "Meta-Experience" component in the MEL approach.
* The "Meta-Experience" component allows for knowledge-level optimization, which is absent in the Standard RLVR.
* The visual representation suggests that the MEL approach leads to a more positive outcome (happy robot with a lightbulb) compared to the Standard RLVR (sad robot).
### Interpretation
The diagram illustrates the advantage of incorporating meta-experience into reinforcement learning. The Standard RLVR relies solely on trajectory-level optimization based on immediate rewards. In contrast, the MEL approach leverages meta-experience to learn higher-level knowledge, which can then be used to improve the agent's performance. The "bifurcation point, critique, heuristic" subtext suggests that the meta-experience component analyzes decision points, provides critiques of past actions, and develops heuristics for future actions. This allows the agent to learn more effectively and achieve better results, as indicated by the happy robot with a lightbulb. The dashed box around the nodes in the MEL diagram might indicate that this part of the process is encapsulated or treated as a single unit within the larger system.