\n
## Diagram: RLVR vs. MEL Frameworks
### Overview
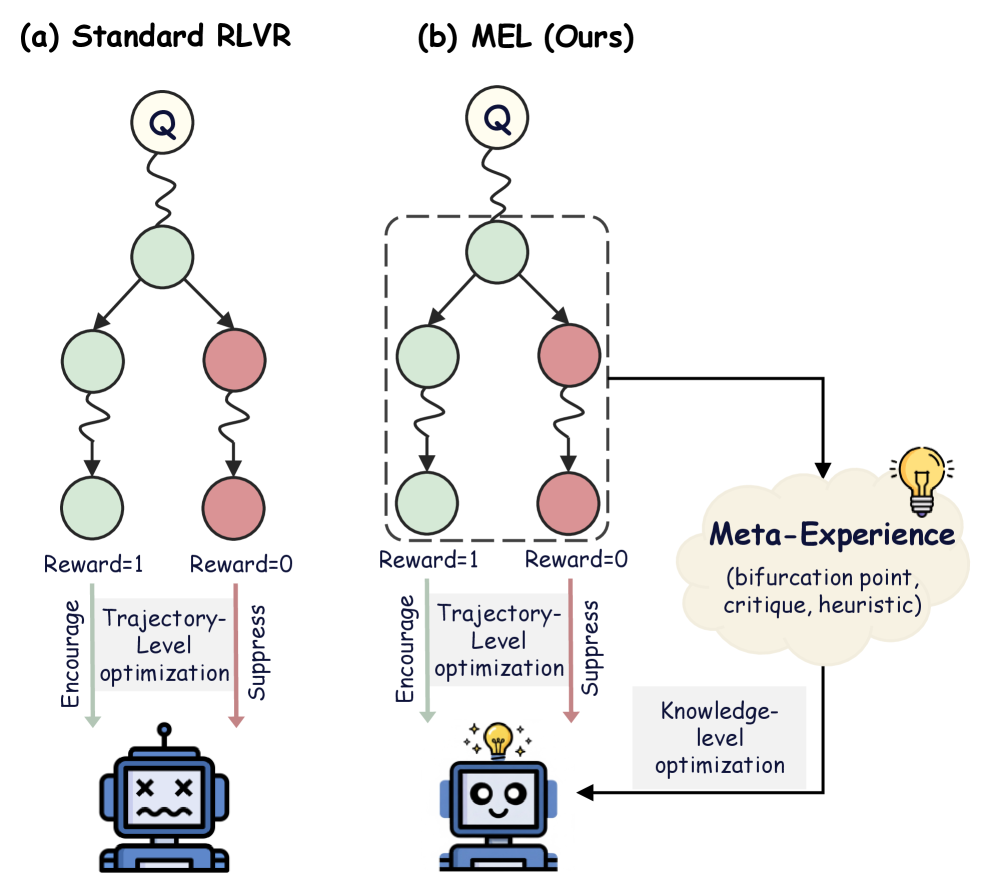
The image presents a comparative diagram illustrating two Reinforcement Learning from Visual Representations (RLVR) frameworks: "Standard RLVR" (a) and "MEL (Ours)" (b). Both frameworks involve a series of nodes connected by directed edges, representing a process of optimization and feedback. The key difference lies in the integration of a "Meta-Experience" component in the MEL framework, which influences a "Knowledge-level optimization" loop. Both diagrams feature a robot icon at the bottom, representing the agent interacting with the environment.
### Components/Axes
The diagram consists of the following key components:
* **Nodes:** Represented as circles, colored light green and light red.
* **Edges:** Represented as curved arrows, indicating the flow of information or influence.
* **Labels:** Textual descriptions associated with nodes, edges, and overall framework components.
* **Robot Icon:** A stylized robot head with crossed eyes, positioned at the bottom of each framework.
* **Meta-Experience Box:** A rectangular box containing text describing the concept of Meta-Experience.
* **Titles:** "(a) Standard RLVR" and "(b) MEL (Ours)" indicating the two frameworks being compared.
* **Reward Labels:** "Reward=1" and "Reward=0" associated with edges in the Standard RLVR framework.
* **Encourage/Suppress Labels:** "Encourage" and "Suppress" associated with vertical arrows.
* **Optimization Labels:** "Trajectory-Level optimization" and "Knowledge-level optimization".
### Detailed Analysis or Content Details
**Standard RLVR (a):**
* The framework consists of six circular nodes arranged in a roughly circular pattern.
* Three nodes are light green, and three are light red.
* Edges connect the nodes in a complex network.
* Edges originating from the green nodes are labeled "Reward=1".
* Edges originating from the red nodes are labeled "Reward=0".
* Two vertical arrows labeled "Encourage" and "Suppress" connect to the robot icon.
* The robot icon has crossed eyes.
* The top node is labeled with a "Q" inside a circle.
**MEL (Ours) (b):**
* Similar to Standard RLVR, this framework also has six circular nodes (three light green, three light red) arranged in a circular pattern.
* Edges connect the nodes, but the pattern differs slightly from Standard RLVR.
* Edges originating from the green nodes are labeled "Reward=1".
* Edges originating from the red nodes are labeled "Reward=0".
* Two vertical arrows labeled "Encourage" and "Suppress" connect to the robot icon.
* The robot icon has a diamond on its head.
* The top node is labeled with a "Q" inside a circle.
* A dashed line connects the framework to a rectangular box labeled "Meta-Experience (bifurcation point, critique, heuristic)".
* An arrow originates from the "Meta-Experience" box and points towards the robot icon, labeled "Knowledge-level optimization".
**Meta-Experience Box:**
* The box is positioned to the right of the MEL framework.
* It contains the text: "Meta-Experience (bifurcation point, critique, heuristic)".
* A lightbulb icon is present within the box.
### Key Observations
* Both frameworks share a similar structure of nodes and edges, but the connections and the addition of the "Meta-Experience" component differentiate MEL from Standard RLVR.
* The "Reward" labels indicate a reinforcement learning process where positive rewards (Reward=1) encourage certain actions, while zero rewards (Reward=0) suppress them.
* The robot icon's change in appearance (crossed eyes vs. diamond) may signify a difference in the agent's state or capabilities between the two frameworks.
* The "Meta-Experience" component in MEL introduces a higher level of abstraction and learning, potentially allowing the agent to adapt more effectively.
### Interpretation
The diagram illustrates a proposed improvement to the Standard RLVR framework by incorporating a "Meta-Experience" component into the MEL framework. The Standard RLVR relies solely on trajectory-level optimization based on immediate rewards. In contrast, MEL introduces a knowledge-level optimization loop informed by meta-experience, which encompasses higher-level concepts like identifying bifurcation points, providing critique, and applying heuristics. This suggests that MEL aims to enable the agent to learn not just *what* actions to take, but *why* those actions are effective, leading to more robust and adaptable behavior. The difference in the robot icon's appearance could indicate that the MEL framework results in a more "aware" or "intelligent" agent. The dashed line connecting the framework to the Meta-Experience box suggests that the meta-experience is not directly part of the core RL loop but rather provides an external influence on the learning process. The diagram is a conceptual illustration of a proposed architecture and does not contain specific numerical data or performance metrics. It is a high-level overview of the framework's components and their relationships.