## Chart: Test Accuracy vs Communication Round for FedProto and FedMRL
### Overview
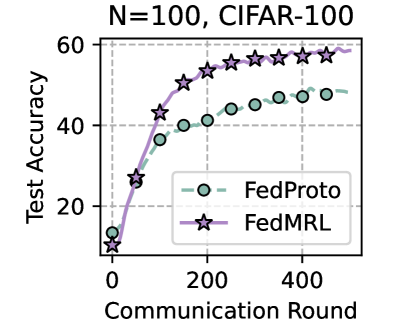
The image is a line chart comparing the test accuracy of two federated learning algorithms, FedProto and FedMRL, over a number of communication rounds. The chart displays the performance of these algorithms on the CIFAR-100 dataset with N=100.
### Components/Axes
* **Title:** N=100, CIFAR-100
* **X-axis:** Communication Round
* Scale: 0 to 500, with visible ticks at 0, 200, and 400.
* **Y-axis:** Test Accuracy
* Scale: 0 to 60, with visible ticks at 0, 20, 40, and 60.
* **Legend:** Located in the bottom-right of the chart.
* FedProto: Represented by a dashed light green line with circle markers.
* FedMRL: Represented by a solid purple line with star markers.
* **Grid:** The chart has a light gray dashed grid.
### Detailed Analysis
* **FedProto (light green, dashed line, circle markers):**
* Trend: The line slopes upward, indicating increasing test accuracy with more communication rounds, and then plateaus.
* Data Points:
* Round 0: Accuracy ~13
* Round 100: Accuracy ~40
* Round 200: Accuracy ~40
* Round 300: Accuracy ~44
* Round 400: Accuracy ~47
* Round 500: Accuracy ~47
* **FedMRL (purple, solid line, star markers):**
* Trend: The line slopes upward, indicating increasing test accuracy with more communication rounds, and then plateaus.
* Data Points:
* Round 0: Accuracy ~10
* Round 100: Accuracy ~43
* Round 200: Accuracy ~52
* Round 300: Accuracy ~56
* Round 400: Accuracy ~56
* Round 500: Accuracy ~58
### Key Observations
* Both algorithms show an increase in test accuracy as the number of communication rounds increases.
* FedMRL consistently outperforms FedProto in terms of test accuracy across all communication rounds.
* Both algorithms appear to plateau in performance after approximately 300 communication rounds.
### Interpretation
The chart demonstrates the performance of two federated learning algorithms on the CIFAR-100 dataset. FedMRL achieves higher test accuracy compared to FedProto, suggesting it is a more effective algorithm for this particular task and dataset. The plateauing of both algorithms indicates a point of diminishing returns, where further communication rounds do not significantly improve the test accuracy. This information is valuable for optimizing the training process and selecting the most efficient algorithm for federated learning tasks.