## Pie Chart: Q1 - Did GPT4 correctly identify the presence or lack of a pattern?
### Overview
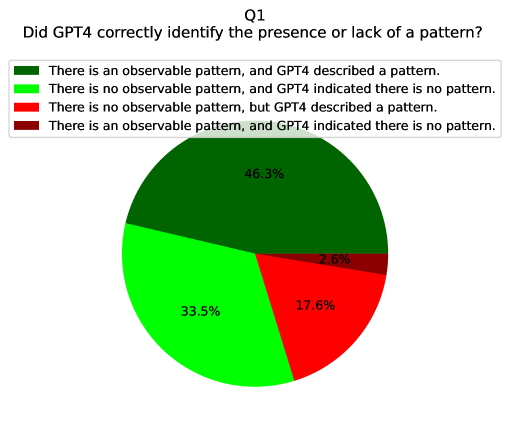
The chart evaluates GPT4's accuracy in identifying patterns, segmented into four categories based on pattern presence and GPT4's responses. The largest segment (46.3%) represents correct pattern identification, followed by correct non-pattern identification (33.5%). Errors include false positives (17.6%) and false negatives (2.6%).
### Components/Axes
- **Legend**: Positioned at the top, with four color-coded categories:
1. **Dark Green**: "There is an observable pattern, and GPT4 described a pattern." (46.3%)
2. **Light Green**: "There is no observable pattern, and GPT4 indicated there is no pattern." (33.5%)
3. **Red**: "There is no observable pattern, but GPT4 described a pattern." (17.6%)
4. **Dark Red**: "There is an observable pattern, and GPT4 indicated there is no pattern." (2.6%)
- **Pie Chart**: Circular visualization with segments proportional to percentages. Segments are ordered clockwise starting with dark green (largest), followed by light green, red, and dark red (smallest).
### Detailed Analysis
- **Correct Pattern Identification**: Dark green segment (46.3%) dominates, indicating GPT4 accurately detected patterns in nearly half of cases.
- **Correct Non-Pattern Identification**: Light green segment (33.5%) shows GPT4 correctly identified absence of patterns in over a third of cases.
- **False Positives**: Red segment (17.6%) highlights instances where GPT4 incorrectly described patterns where none existed.
- **False Negatives**: Dark red segment (2.6%) represents cases where GPT4 failed to detect existing patterns.
### Key Observations
- **Majority Accuracy**: Combined correct identifications (79.8%) suggest GPT4 performs well overall.
- **Error Distribution**: False positives (17.6%) outnumber false negatives (2.6%), indicating a bias toward over-identifying patterns.
- **Smallest Segment**: Dark red (2.6%) is visually distinct as the smallest slice, emphasizing rare failures to detect patterns.
### Interpretation
The data suggests GPT4 has strong pattern recognition capabilities but exhibits a tendency to over-identify patterns in ambiguous cases (false positives). The low false negative rate (2.6%) implies it is more reliable at confirming patterns when they exist. However, the 17.6% false positive rate raises questions about its threshold for pattern detection—potentially prioritizing sensitivity over specificity. This could be critical in applications where false alarms are costly (e.g., medical diagnostics). The chart underscores the need for context-aware adjustments to GPT4's pattern recognition parameters.