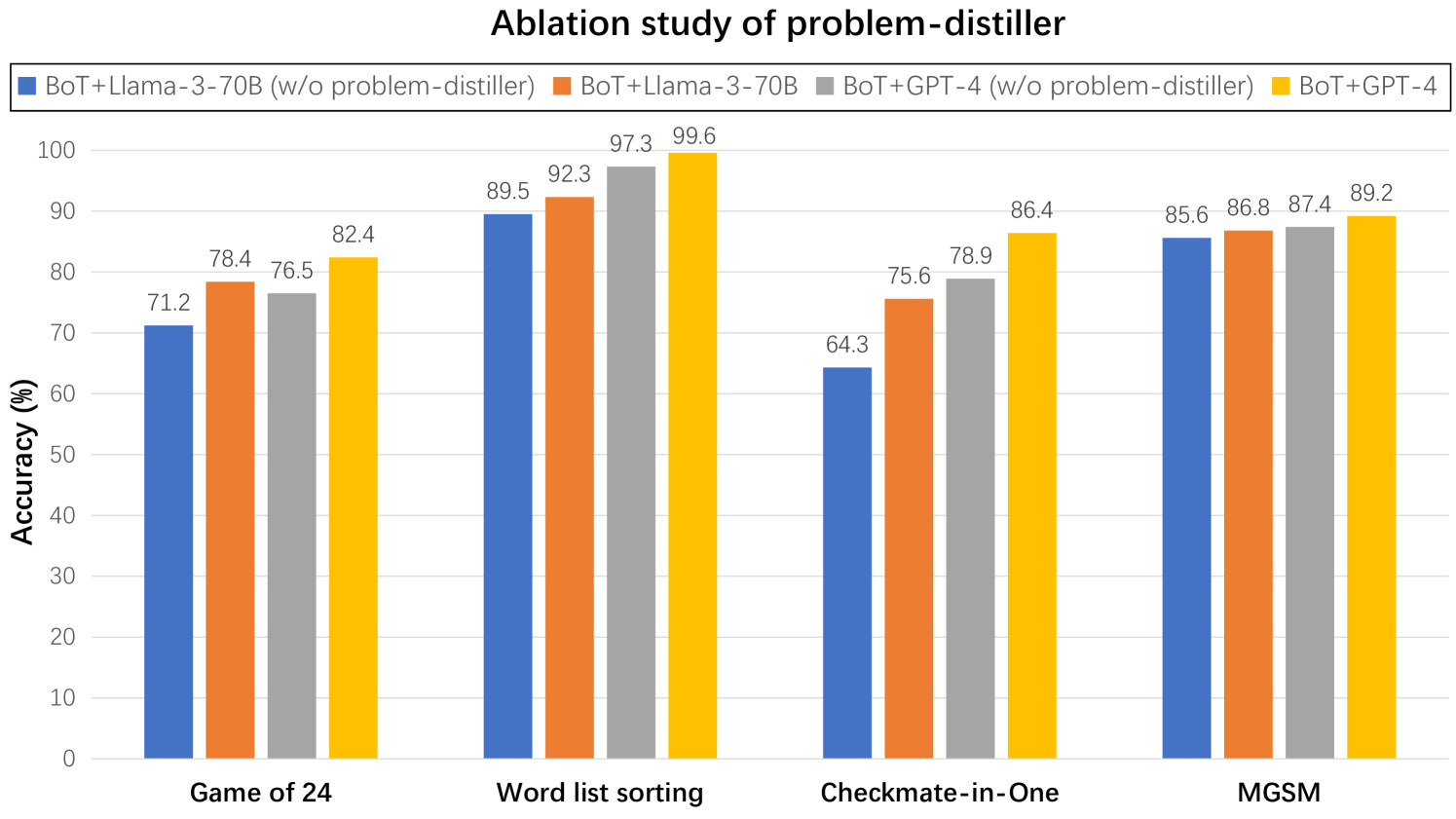
## Bar Chart: Ablation study of problem-distiller
### Overview
The image is a bar chart comparing the accuracy (%) of different models (BoT+Llama-3-70B with/without problem-distiller and BoT+GPT-4 with/without problem-distiller) across four tasks: Game of 24, Word list sorting, Checkmate-in-One, and MGSM. The chart visually represents the performance of each model on each task, allowing for a direct comparison of their effectiveness.
### Components/Axes
* **Title:** Ablation study of problem-distiller
* **Y-axis:**
* Label: Accuracy (%)
* Scale: 0 to 100, with tick marks at intervals of 10.
* **X-axis:**
* Categories: Game of 24, Word list sorting, Checkmate-in-One, MGSM
* **Legend:** Located at the top of the chart.
* Blue: BoT+Llama-3-70B (w/o problem-distiller)
* Orange: BoT+Llama-3-70B
* Gray: BoT+GPT-4 (w/o problem-distiller)
* Yellow: BoT+GPT-4
### Detailed Analysis
**Game of 24:**
* BoT+Llama-3-70B (w/o problem-distiller) (Blue): 71.2%
* BoT+Llama-3-70B (Orange): 78.4%
* BoT+GPT-4 (w/o problem-distiller) (Gray): 76.5%
* BoT+GPT-4 (Yellow): 82.4%
**Word list sorting:**
* BoT+Llama-3-70B (w/o problem-distiller) (Blue): 89.5%
* BoT+Llama-3-70B (Orange): 92.3%
* BoT+GPT-4 (w/o problem-distiller) (Gray): 97.3%
* BoT+GPT-4 (Yellow): 99.6%
**Checkmate-in-One:**
* BoT+Llama-3-70B (w/o problem-distiller) (Blue): 64.3%
* BoT+Llama-3-70B (Orange): 75.6%
* BoT+GPT-4 (w/o problem-distiller) (Gray): 78.9%
* BoT+GPT-4 (Yellow): 86.4%
**MGSM:**
* BoT+Llama-3-70B (w/o problem-distiller) (Blue): 85.6%
* BoT+Llama-3-70B (Orange): 86.8%
* BoT+GPT-4 (w/o problem-distiller) (Gray): 87.4%
* BoT+GPT-4 (Yellow): 89.2%
### Key Observations
* The "Word list sorting" task has the highest accuracy across all models.
* The "Checkmate-in-One" task generally has the lowest accuracy across all models.
* BoT+GPT-4 (Yellow) generally outperforms BoT+Llama-3-70B (Blue) on all tasks.
* The problem-distiller seems to improve performance in most cases, as the orange and yellow bars are generally higher than the blue and gray bars, respectively.
### Interpretation
The chart presents an ablation study, which aims to understand the impact of removing a specific component (the "problem-distiller") from the models. The data suggests that the problem-distiller generally improves the accuracy of both BoT+Llama-3-70B and BoT+GPT-4 models across the tested tasks. The BoT+GPT-4 model consistently achieves higher accuracy compared to BoT+Llama-3-70B, indicating that GPT-4 is a more effective base model for these tasks. The "Word list sorting" task appears to be relatively easier for these models, while "Checkmate-in-One" poses a greater challenge. The performance difference between models with and without the problem-distiller highlights the importance of this component in achieving optimal accuracy.