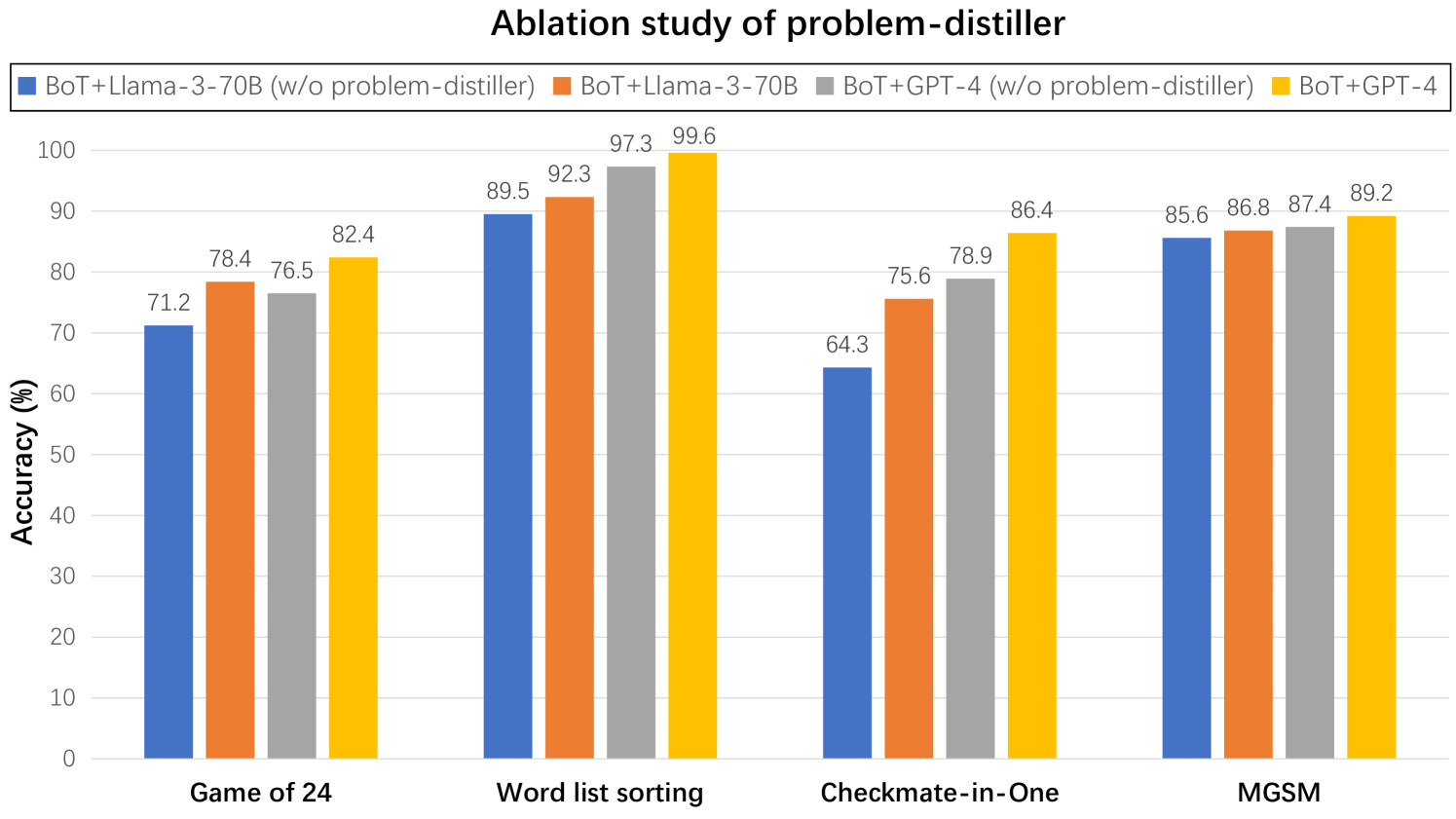
## Bar Chart: Ablation study of problem-distiller
### Overview
This is a grouped bar chart titled "Ablation study of problem-distiller." It compares the accuracy (in percentage) of four different model configurations across four distinct reasoning tasks. The chart evaluates the impact of a "problem-distiller" component by showing performance both with and without it for two base models (Llama-3-70B and GPT-4).
### Components/Axes
* **Chart Title:** "Ablation study of problem-distiller" (centered at the top).
* **Y-Axis:** Labeled "Accuracy (%)". The scale runs from 0 to 100 in increments of 10.
* **X-Axis:** Lists four task categories: "Game of 24", "Word list sorting", "Checkmate-in-One", and "MGSM".
* **Legend:** Positioned at the top of the chart, below the title. It defines four data series by color:
* **Blue:** BoT+Llama-3-70B (w/o problem-distiller)
* **Orange:** BoT+Llama-3-70B
* **Grey:** BoT+GPT-4 (w/o problem-distiller)
* **Yellow:** BoT+GPT-4
* *Note: "w/o" is an abbreviation for "without".*
### Detailed Analysis
The chart presents accuracy data for each of the four tasks. The values are extracted directly from the labels above each bar.
| Task | BoT+Llama-3-70B (w/o problem-distiller) [Blue] | BoT+Llama-3-70B [Orange] | BoT+GPT-4 (w/o problem-distiller) [Grey] | BoT+GPT-4 [Yellow] |
| :--- | :--- | :--- | :--- | :--- |
| **Game of 24** | 71.2% | 78.4% | 76.5% | 82.4% |
| **Word list sorting** | 89.5% | 92.3% | 97.3% | 99.6% |
| **Checkmate-in-One** | 64.3% | 75.6% | 78.9% | 86.4% |
| **MGSM** | 85.6% | 86.8% | 87.4% | 89.2% |
### Key Observations
* **Consistent Improvement:** For every task and both base models (Llama-3-70B and GPT-4), the configuration *with* the problem-distiller (Orange and Yellow bars) achieves higher accuracy than the configuration *without* it (Blue and Grey bars).
* **Model Performance Hierarchy:** The BoT+GPT-4 configuration (Yellow) consistently achieves the highest accuracy across all four tasks. The BoT+Llama-3-70B (w/o problem-distiller) (Blue) consistently has the lowest accuracy.
* **Task Variability:** The magnitude of improvement from adding the problem-distiller varies by task. The largest absolute gains are seen in "Checkmate-in-One" (+11.3% for Llama-3, +7.5% for GPT-4) and "Game of 24" (+7.2% for Llama-3, +5.9% for GPT-4). The smallest gains are in "MGSM" (+1.2% for Llama-3, +1.8% for GPT-4).
* **Near-Perfect Performance:** The BoT+GPT-4 model achieves 99.6% accuracy on the "Word list sorting" task, which is the highest value on the chart.
### Interpretation
This ablation study provides strong empirical evidence for the efficacy of the "problem-distiller" component. The data suggests that integrating this component systematically improves the reasoning accuracy of large language models (LLaMA-3-70B and GPT-4) when they are used within the "BoT" (likely "Brain of Thought" or similar) framework.
The consistent positive delta across diverse tasks—from mathematical puzzles (Game of 24, MGSM) to logical sequencing (Word list sorting) and strategic planning (Checkmate-in-One)—indicates that the problem-distiller is a generally beneficial module, not one specialized for a single type of problem. The fact that it boosts both a smaller open-source model (Llama-3-70B) and a larger proprietary model (GPT-4) suggests it addresses a fundamental challenge in problem representation or decomposition that is common across model architectures.
The varying degree of improvement implies that some tasks (like Checkmate-in-One) benefit more from the problem-distiller's intervention than others (like MGSM). This could be because MGSM tasks are already well-structured for the base models, or because the problem-distiller's specific methodology is particularly adept at clarifying the kind of multi-step, state-based reasoning required for chess puzzles. The near-ceiling performance on "Word list sorting" (99.6%) suggests this task may be approaching saturation for the GPT-4-based system with this augmentation.