## Bar Chart: Ablation study of problem-distiller
### Overview
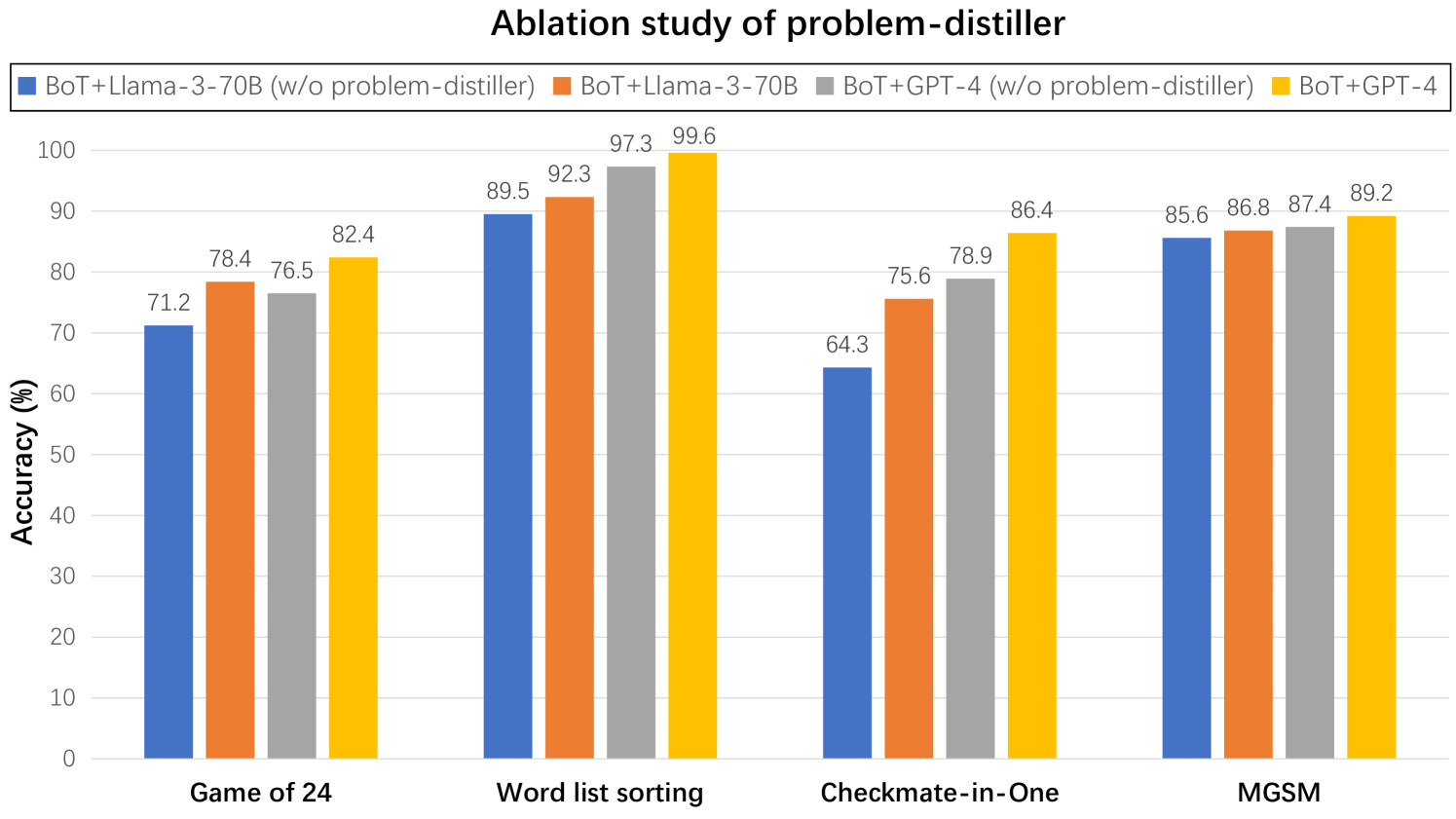
The chart compares the accuracy of four model configurations across four tasks: Game of 24, Word list sorting, Checkmate-in-One, and MGSM. Each task is represented by a group of four bars, with colors corresponding to specific model combinations. The y-axis measures accuracy in percentage, ranging from 0 to 100.
### Components/Axes
- **X-axis (Tasks)**:
- Game of 24
- Word list sorting
- Checkmate-in-One
- MGSM
- **Y-axis (Accuracy)**:
- Scale: 0% to 100% in 10% increments
- Label: "Accuracy (%)"
- **Legend (Top-left)**:
- Blue: BoT+Llama-3-70B (w/o problem-distiller)
- Orange: BoT+Llama-3-70B
- Gray: BoT+GPT-4 (w/o problem-distiller)
- Yellow: BoT+GPT-4
### Detailed Analysis
#### Task: Game of 24
- Blue (BoT+Llama-3-70B w/o): 71.2%
- Orange (BoT+Llama-3-70B): 78.4%
- Gray (BoT+GPT-4 w/o): 76.5%
- Yellow (BoT+GPT-4): 82.4%
#### Task: Word list sorting
- Blue (BoT+Llama-3-70B w/o): 89.5%
- Orange (BoT+Llama-3-70B): 92.3%
- Gray (BoT+GPT-4 w/o): 97.3%
- Yellow (BoT+GPT-4): 99.6%
#### Task: Checkmate-in-One
- Blue (BoT+Llama-3-70B w/o): 64.3%
- Orange (BoT+Llama-3-70B): 75.6%
- Gray (BoT+GPT-4 w/o): 78.9%
- Yellow (BoT+GPT-4): 86.4%
#### Task: MGSM
- Blue (BoT+Llama-3-70B w/o): 85.6%
- Orange (BoT+Llama-3-70B): 86.8%
- Gray (BoT+GPT-4 w/o): 87.4%
- Yellow (BoT+GPT-4): 89.2%
### Key Observations
1. **Problem-distiller impact**:
- Orange/yellow bars (with problem-distiller) consistently outperform blue/gray bars (without) across all tasks.
- Largest improvement: Word list sorting (BoT+GPT-4: +2.3% with problem-distiller).
2. **Model performance**:
- BoT+GPT-4 models (yellow/gray) generally outperform BoT+Llama-3-70B (orange/blue).
- Checkmate-in-One shows the lowest accuracy overall (64.3% baseline).
3. **Task difficulty**:
- Word list sorting achieves near-perfect accuracy (99.6% peak).
- Checkmate-in-One has the largest performance gap between models (+22.1% between lowest and highest).
### Interpretation
The data demonstrates that the problem-distiller significantly enhances model performance across all tasks, with the most dramatic improvement observed in Word list sorting. BoT+GPT-4 models consistently outperform BoT+Llama-3-70B, suggesting GPT-4's superior base capabilities. Checkmate-in-One's lower accuracy highlights its complexity compared to other tasks. The ablation study confirms that problem-distillation is critical for optimizing model performance, particularly for GPT-4-based systems.