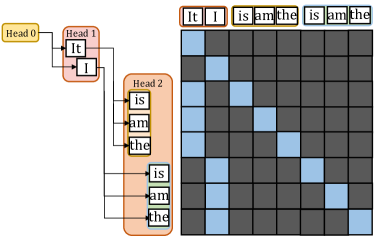
## Diagram: Attention Head Visualization
### Overview
The image presents a visualization of attention heads in a neural network, likely a transformer model. It shows how different heads focus on different parts of the input sequence. The diagram consists of a tree-like structure representing attention heads and a matrix visualizing the attention weights.
### Components/Axes
* **Attention Heads:** The diagram shows three attention heads, labeled "Head 0", "Head 1", and "Head 2".
* **Input Sequence:** The input sequence is "It I is am the is am the". This sequence is represented both in the tree structure and as labels along the top and left of the attention matrix.
* **Attention Matrix:** A 9x9 matrix visualizes the attention weights. Each cell represents the attention weight between two words in the input sequence. Blue cells indicate a high attention weight, while dark gray cells indicate a low attention weight.
### Detailed Analysis
* **Head 0:** The "Head 0" node is colored yellow and does not appear to have any direct connections to the input sequence.
* **Head 1:** The "Head 1" node is colored red and is connected to "It" and "I".
* **Head 2:** The "Head 2" node is colored orange and is connected to "is", "am", "the", "is", "am", and "the".
* **Attention Matrix:**
* The matrix is a 9x9 grid.
* The x-axis and y-axis are labeled with the input sequence: "It I is am the is am the".
* The cells are colored either blue (high attention) or dark gray (low attention).
* The diagonal elements show some attention, but there are also off-diagonal elements with significant attention.
* The first "It" attends to itself.
* The "I" attends to itself.
* The first "is" attends to itself.
* The first "am" attends to itself.
* The first "the" attends to itself.
* The second "is" attends to itself.
* The second "am" attends to itself.
* The second "the" attends to itself.
### Key Observations
* Different attention heads focus on different parts of the input sequence.
* The attention matrix shows the specific attention weights between words.
* The diagonal elements of the attention matrix show that each word attends to itself to some extent.
### Interpretation
The diagram illustrates how attention mechanisms work in neural networks. It shows that different attention heads can focus on different parts of the input sequence, allowing the model to capture complex relationships between words. The attention matrix provides a detailed view of the attention weights, showing which words are most relevant to each other. This visualization helps to understand how the model is processing the input sequence and making predictions. The fact that Head 0 is not connected to any words suggests it might be learning a different aspect of the data or is not actively contributing to this specific input.