## Diagram: Attention Mechanism in a Transformer Model
### Overview
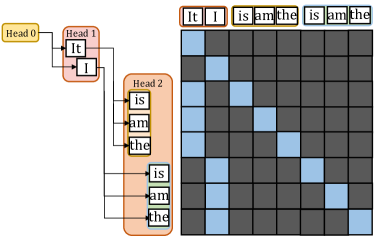
The image depicts a simplified visualization of an attention mechanism in a transformer model, illustrating how different "heads" (components of the model) process and relate to input words. The diagram includes three labeled heads (Head 0, Head 1, Head 2) connected to a grid of words, with colored squares indicating attention weights.
### Components/Axes
1. **Heads**:
- **Head 0** (yellow): Contains words "It" and "I".
- **Head 1** (pink): Contains words "It" and "I".
- **Head 2** (orange): Contains words "is," "am," "the," "is," "am," "the".
2. **Grid**:
- A 6x6 matrix of squares (rows and columns labeled with words: "It," "I," "is," "am," "the").
- **Colors**:
- **Blue**: High attention weights.
- **Gray**: Low attention weights.
- **Axes**:
- **Rows**: Labeled with words from Head 2 ("is," "am," "the," "is," "am," "the").
- **Columns**: Labeled with words from Head 0 and Head 1 ("It," "I," "is," "am," "the").
### Detailed Analysis
1. **Head Connections**:
- Arrows from Head 0 and Head 1 point to Head 2, indicating input flow.
- Head 2 distributes attention to the grid, with blue squares highlighting key connections.
2. **Grid Patterns**:
- **Blue Squares**:
- Head 0's "It" connects to Head 1's "I" (top-left blue cluster).
- Head 2's "is" and "am" connect to Head 1's "I" (middle-left blue squares).
- Head 2's "the" connects to Head 0's "It" (bottom-right blue squares).
- **Gray Squares**: Mostly dominate the grid, indicating sparse attention.
### Key Observations
1. **Repetition in Head 2**: The repeated words "is," "am," "the" suggest a focus on grammatical structure (auxiliary verbs and articles).
2. **Attention Concentration**: Blue squares cluster around specific word pairs (e.g., "It" → "I," "is" → "I"), indicating strong contextual relationships.
3. **Sparse Attention**: Most grid cells are gray, reflecting the model's selective focus on critical word interactions.
### Interpretation
This diagram demonstrates how transformer models use attention mechanisms to prioritize relationships between words. The repetition in Head 2 highlights the model's emphasis on grammatical roles, while the blue squares in the grid reveal how specific word pairs (e.g., pronouns and verbs) are dynamically linked. The sparse attention pattern underscores the efficiency of transformers in focusing computational resources on meaningful connections, enabling context-aware language processing. The diagram aligns with known transformer behavior, where attention heads specialize in different linguistic features (e.g., syntax, semantics).