\n
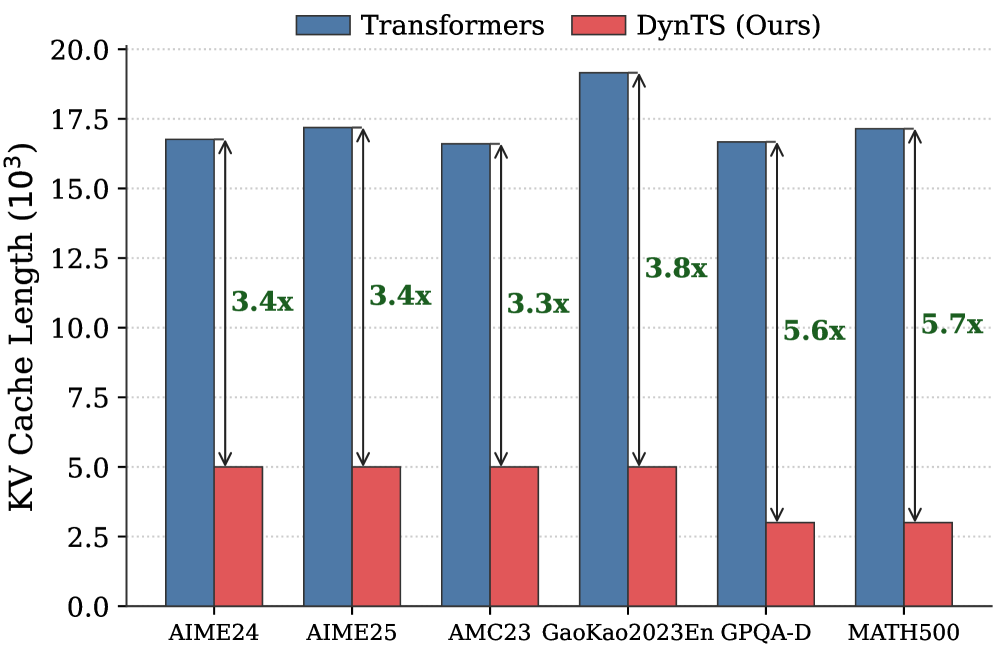
## Bar Chart: KV Cache Length Comparison - Transformers vs. DynTS
### Overview
This bar chart compares the KV Cache Length (in 10^3 units) for two models, "Transformers" and "DynTS (Ours)", across six different datasets: AIME24, AIME25, AMC23, GaoKao2023En, GPQA-D, and MATH500. The chart visually represents the performance difference in terms of KV cache usage between the two models on each dataset. Above each DynTS bar is a multiplier indicating how much smaller the cache length is compared to the Transformers model.
### Components/Axes
* **X-axis:** Dataset names: AIME24, AIME25, AMC23, GaoKao2023En, GPQA-D, MATH500.
* **Y-axis:** KV Cache Length (10^3). Scale ranges from 0.0 to 20.0.
* **Legend:**
* Blue: Transformers
* Red: DynTS (Ours)
* **Labels:** Each DynTS bar has a label indicating the compression factor relative to the Transformers model (e.g., "3.4x").
### Detailed Analysis
The chart consists of paired bars for each dataset, representing the KV Cache Length for Transformers and DynTS.
* **AIME24:** Transformers: approximately 16.5. DynTS: approximately 4.8. Compression factor: 3.4x.
* **AIME25:** Transformers: approximately 17.0. DynTS: approximately 5.0. Compression factor: 3.4x.
* **AMC23:** Transformers: approximately 16.8. DynTS: approximately 5.0. Compression factor: 3.3x.
* **GaoKao2023En:** Transformers: approximately 19.0. DynTS: approximately 5.0. Compression factor: 3.8x.
* **GPQA-D:** Transformers: approximately 10.5. DynTS: approximately 1.9. Compression factor: 5.6x.
* **MATH500:** Transformers: approximately 17.0. DynTS: approximately 2.4. Compression factor: 5.7x.
The Transformers bars are consistently higher than the DynTS bars across all datasets, indicating a larger KV Cache Length for Transformers.
### Key Observations
* DynTS consistently uses significantly less KV cache than Transformers across all datasets.
* The compression factor varies between 3.3x and 5.7x, with the largest compression achieved on the GPQA-D and MATH500 datasets.
* The difference in KV Cache Length is most pronounced on the GPQA-D and MATH500 datasets.
* The KV Cache Length for Transformers is relatively consistent across all datasets, ranging from approximately 10.5 to 19.0.
### Interpretation
The data suggests that DynTS is a more KV cache-efficient model compared to Transformers. This is particularly evident on the GPQA-D and MATH500 datasets, where DynTS achieves a compression factor of 5.6x and 5.7x, respectively. This could be due to the DynTS architecture being better suited for these specific datasets, or it could indicate a more general advantage in terms of KV cache management. The consistent reduction in KV Cache Length across all datasets suggests that DynTS's efficiency is not dataset-specific. The relatively stable KV Cache Length for Transformers indicates that the model's memory requirements are less sensitive to the input data. The multiplier labels directly highlight the benefit of using DynTS, quantifying the reduction in memory usage. This is important because KV cache size is a significant factor in the computational cost and scalability of transformer-based models.