\n
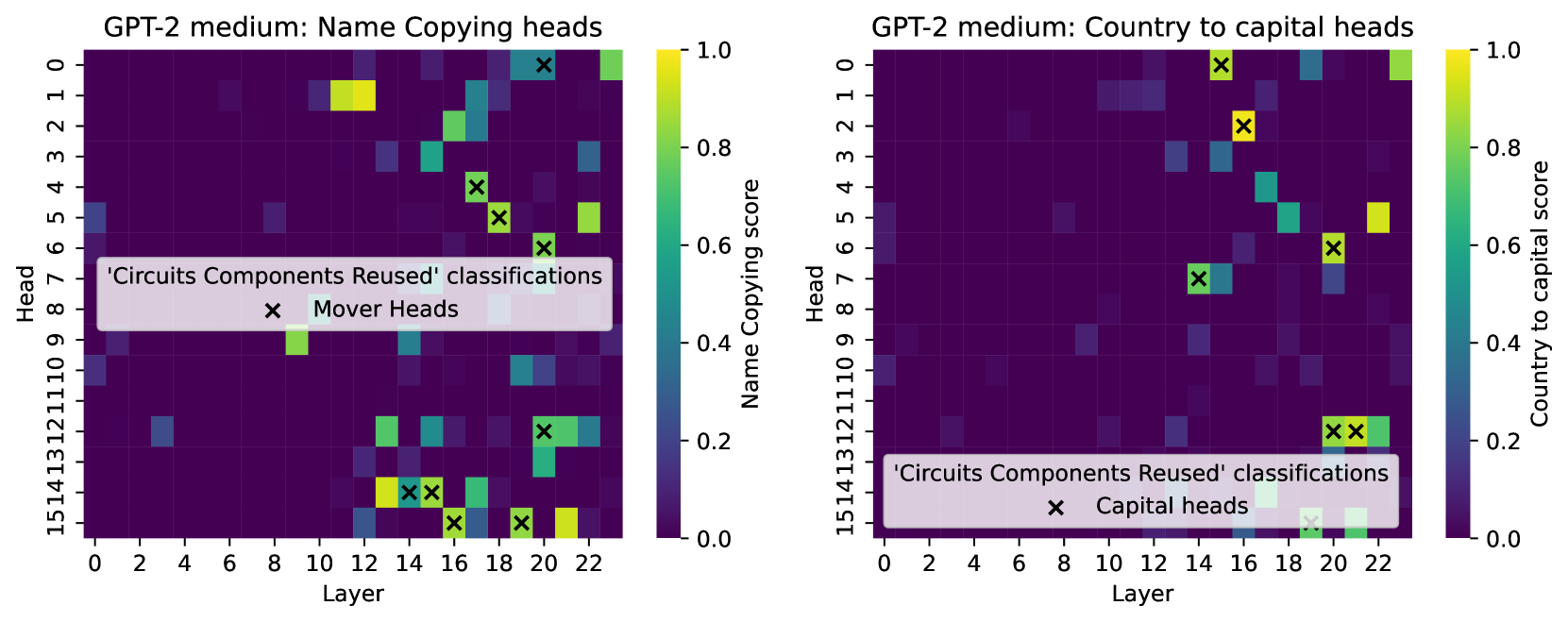
## Heatmaps: GPT-2 Medium Head Analysis
### Overview
The image presents two heatmaps, side-by-side, visualizing data related to GPT-2 medium model heads. The first heatmap shows "Name Copying heads" and the second shows "Country to capital heads". Both heatmaps share the same x and y axes, representing 'Layer' and 'Head' respectively. Both heatmaps also include 'Mover Heads' or 'Capital heads' marked with 'x' symbols. The color intensity in each heatmap represents a score, with a scale from 0.0 to 1.0.
### Components/Axes
* **X-axis:** Layer, ranging from 0 to 22.
* **Y-axis:** Head, ranging from 0 to 15.
* **Color Scale (Left):** Name Copying score, ranging from 0.0 (dark purple) to 1.0 (yellow).
* **Color Scale (Right):** Country to capital score, ranging from 0.0 (dark purple) to 1.0 (yellow).
* **Markers:** 'x' symbols representing 'Mover Heads' in the left heatmap and 'Capital heads' in the right heatmap.
* **Text Label (Both):** 'Circuits Components Reused' classifications.
* **Title (Left):** GPT-2 medium: Name Copying heads
* **Title (Right):** GPT-2 medium: Country to capital heads
### Detailed Analysis or Content Details
**Left Heatmap: Name Copying Heads**
The heatmap displays the 'Name Copying score' for each head at each layer. The color intensity indicates the score.
* **Trend:** The heatmap shows a sparse distribution of high scores (yellow/light green). There are several areas with moderate scores (blue/cyan). The majority of the heatmap is dark purple, indicating low scores.
* **Data Points (approximate):**
* Layer 0-6: Predominantly low scores (0.0 - 0.2).
* Layer 8-10: Some moderate scores (0.4 - 0.6) around Head 4 and 5.
* Layer 12-14: Moderate scores (0.4 - 0.6) around Head 2 and 3.
* Layer 16: A high score (approximately 0.8-0.9) around Head 2.
* Layer 18: A high score (approximately 0.9-1.0) around Head 1.
* Layer 20: Moderate scores (0.4-0.6) around Head 14.
* **Mover Heads:** Marked with 'x' symbols. Approximate locations:
* (Layer 14, Head 1)
* (Layer 16, Head 4)
* (Layer 18, Head 6)
* (Layer 20, Head 10)
* (Layer 22, Head 14)
**Right Heatmap: Country to Capital Heads**
The heatmap displays the 'Country to capital score' for each head at each layer. The color intensity indicates the score.
* **Trend:** Similar to the left heatmap, this heatmap also shows a sparse distribution of high scores. There are areas with moderate scores, but the majority is dark purple.
* **Data Points (approximate):**
* Layer 0-6: Predominantly low scores (0.0 - 0.2).
* Layer 8-10: Some moderate scores (0.4 - 0.6) around Head 2 and 3.
* Layer 12-14: Moderate scores (0.4 - 0.6) around Head 2 and 3.
* Layer 16: A high score (approximately 0.8-0.9) around Head 2.
* Layer 18: A high score (approximately 0.9-1.0) around Head 1.
* Layer 20: Moderate scores (0.4-0.6) around Head 14.
* **Capital Heads:** Marked with 'x' symbols. Approximate locations:
* (Layer 14, Head 1)
* (Layer 16, Head 4)
* (Layer 18, Head 6)
* (Layer 20, Head 10)
* (Layer 22, Head 14)
### Key Observations
* Both heatmaps exhibit similar patterns of score distribution.
* High scores are relatively rare and concentrated in specific layers and heads.
* The 'Mover Heads' and 'Capital heads' are located at similar positions in both heatmaps, suggesting a correlation between the two tasks.
* The 'Circuits Components Reused' classifications appear to be a common feature across both analyses.
### Interpretation
The heatmaps visualize the performance of different heads within the GPT-2 medium model on two distinct tasks: name copying and country-to-capital mapping. The scores represent how well each head contributes to these tasks at different layers of the model. The sparse distribution of high scores suggests that only a small subset of heads are particularly effective at these tasks.
The correlation in the location of 'Mover Heads' and 'Capital heads' indicates that the same heads might be involved in processing information relevant to both tasks. This could suggest underlying shared representations or mechanisms within the model.
The 'Circuits Components Reused' classifications likely refer to the fact that certain components or patterns within the neural network are reused across different tasks or layers. This is a common characteristic of deep learning models and contributes to their efficiency and generalization ability.
The heatmaps provide insights into the internal workings of the GPT-2 model, highlighting which heads and layers are most important for specific tasks. This information can be used to further understand the model's capabilities and limitations, and potentially improve its performance. The fact that the high scoring heads are not evenly distributed suggests that the model is not uniformly utilizing all of its parameters for these tasks.