\n
## Horizontal Bar Chart: Logical Consistency of Language Models
### Overview
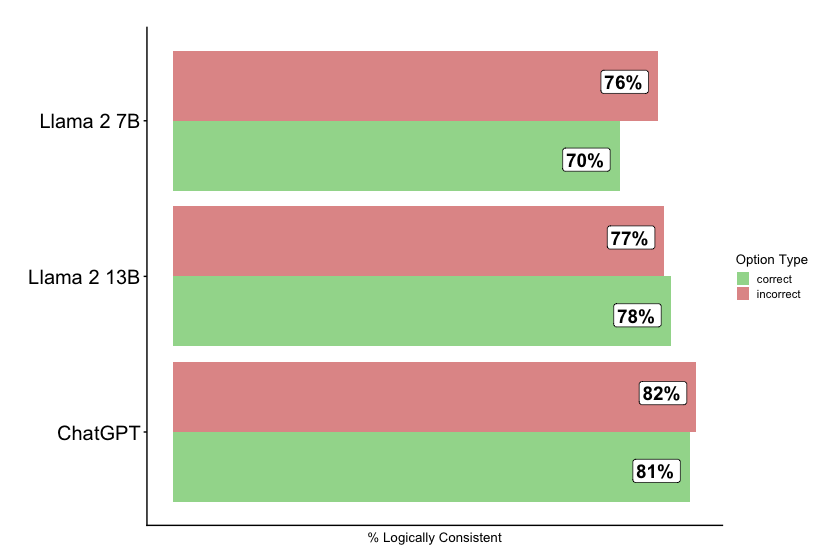
The image presents a horizontal bar chart comparing the percentage of logically consistent responses from three different language models: Llama 2 7B, Llama 2 13B, and ChatGPT. Each model has two bars representing "correct" and "incorrect" responses. The chart aims to visually represent the logical consistency of each model.
### Components/Axes
* **Y-axis:** Lists the language models: Llama 2 7B, Llama 2 13B, and ChatGPT.
* **X-axis:** Labeled "% Logically Consistent". Represents the percentage of logically consistent responses. The scale is not explicitly marked, but ranges from approximately 0% to 85%.
* **Legend:** Located in the top-right corner, defines the color coding:
* Green: "correct"
* Red: "incorrect"
### Detailed Analysis
The chart displays the following data:
* **Llama 2 7B:**
* Incorrect: Approximately 76% (Red bar)
* Correct: Approximately 70% (Green bar)
* **Llama 2 13B:**
* Incorrect: Approximately 77% (Red bar)
* Correct: Approximately 78% (Green bar)
* **ChatGPT:**
* Incorrect: Approximately 82% (Red bar)
* Correct: Approximately 81% (Green bar)
The bars are arranged vertically, with each model's "incorrect" bar positioned to the right of its "correct" bar.
### Key Observations
* ChatGPT has the highest percentage of incorrect responses (82%) and a slightly higher percentage of correct responses (81%) compared to the other models.
* Llama 2 13B has the highest percentage of correct responses (78%) and a similar percentage of incorrect responses (77%).
* Llama 2 7B has the lowest percentage of correct responses (70%) and a slightly lower percentage of incorrect responses (76%).
* For all three models, the percentage of incorrect responses is higher than the percentage of correct responses.
### Interpretation
The data suggests that none of the three language models consistently provide logically sound responses. ChatGPT appears to be the least logically consistent overall, while Llama 2 13B performs slightly better in terms of providing correct responses. The fact that the "incorrect" bars are consistently higher than the "correct" bars across all models indicates a significant challenge in ensuring logical consistency in these large language models. This could be due to various factors, including biases in the training data, limitations in the models' reasoning abilities, or the inherent complexity of natural language. The difference between the 7B and 13B versions of Llama 2 suggests that increasing model size can improve logical consistency, but doesn't eliminate the problem. Further investigation is needed to understand the specific types of logical errors these models are making and to develop strategies for mitigating them.