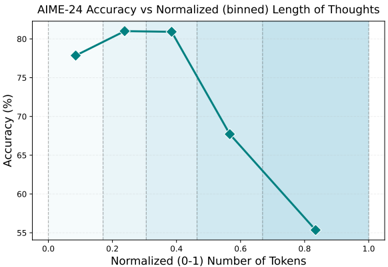
## Chart: AIME-24 Accuracy vs Normalized (binned) Length of Thoughts
### Overview
The image is a line chart showing the relationship between AIME-24 accuracy (in percentage) and the normalized (0-1) number of tokens, which represents the binned length of thoughts. The chart shows how accuracy changes as the length of thoughts increases.
### Components/Axes
* **Title:** AIME-24 Accuracy vs Normalized (binned) Length of Thoughts
* **X-axis:** Normalized (0-1) Number of Tokens. The axis ranges from 0.0 to 1.0, with tick marks at intervals of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
* **Y-axis:** Accuracy (%). The axis ranges from 55% to 80%, with tick marks at intervals of 5% (55, 60, 65, 70, 75, 80).
* **Data Series:** A single teal line represents the accuracy at different normalized token lengths.
* **Background:** The background is divided into vertical sections with alternating white and light blue shading.
### Detailed Analysis
The teal line represents the AIME-24 accuracy. The data points are as follows:
* At 0.0 Normalized Number of Tokens, the accuracy is approximately 77.5%.
* At 0.2 Normalized Number of Tokens, the accuracy is approximately 81%.
* At 0.4 Normalized Number of Tokens, the accuracy is approximately 81%.
* At 0.6 Normalized Number of Tokens, the accuracy is approximately 68%.
* At 0.8 Normalized Number of Tokens, the accuracy is approximately 55.5%.
The trend of the teal line is as follows:
* From 0.0 to 0.2, the line slopes upward.
* From 0.2 to 0.4, the line is relatively flat.
* From 0.4 to 0.8, the line slopes downward.
### Key Observations
* The accuracy peaks at a normalized token length of approximately 0.2 to 0.4.
* The accuracy decreases significantly as the normalized token length increases beyond 0.4.
* The highest accuracy achieved is approximately 81%.
* The lowest accuracy is approximately 55.5%.
### Interpretation
The chart suggests that there is an optimal length of "thoughts" (represented by the number of tokens) for maximizing the accuracy of the AIME-24 model. When the normalized token length is between 0.2 and 0.4, the model achieves its highest accuracy. However, as the length of thoughts increases beyond this range, the accuracy drops significantly. This could indicate that longer, more complex thoughts are more difficult for the model to process accurately, or that the model is better trained on shorter, more concise inputs. The sharp decline in accuracy after 0.4 suggests a potential limitation of the model in handling longer sequences or more complex information.