TECHNICAL ASSET FINGERPRINT
e052d7e4e879e15ccacfd83a
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
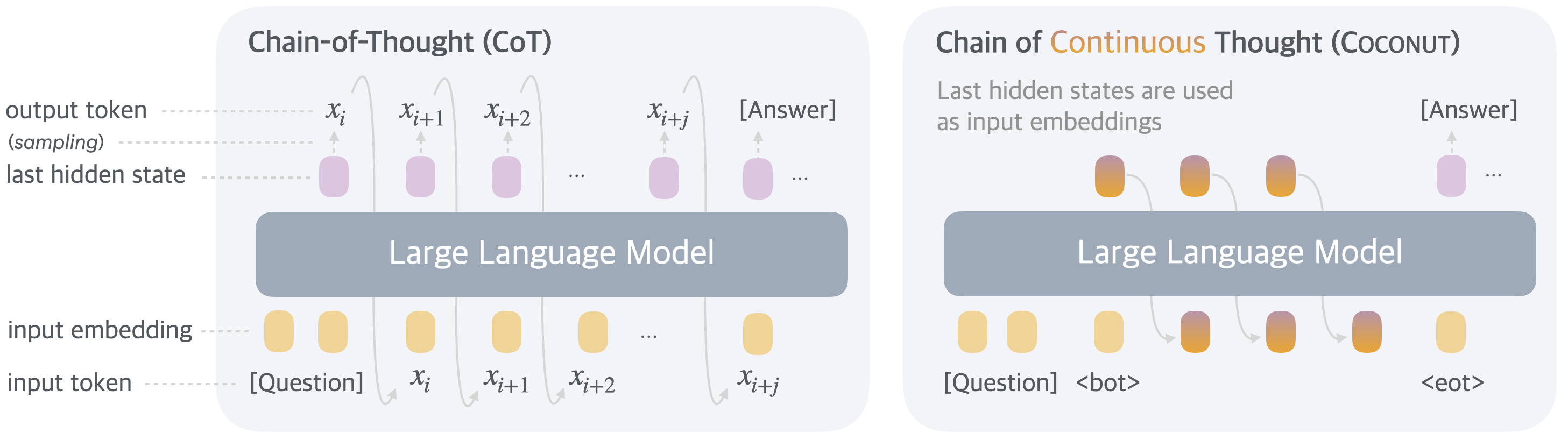
## Diagram: Comparison of Chain-of-Thought (CoT) and Chain of Continuous Thought (Coconut) Reasoning Methods
### Overview
The image is a technical diagram comparing two prompting/reasoning methods for Large Language Models (LLMs). It visually contrasts the standard **Chain-of-Thought (CoT)** process with a proposed **Chain of Continuous Thought (Coconut)** method. The diagram is split into two distinct panels, each illustrating the flow of data through a "Large Language Model" block.
### Components/Axes
The diagram is organized into two main panels, left and right, each with a consistent vertical flow from bottom (input) to top (output).
**Left Panel: Chain-of-Thought (CoT)**
* **Title:** "Chain-of-Thought (CoT)" at the top.
* **Central Component:** A large, grey, rounded rectangle labeled "Large Language Model".
* **Input Layer (Bottom):**
* **Label (left):** "input token"
* **Elements:** A sequence of tokens: `[Question]`, `x_i`, `x_{i+1}`, `x_{i+2}`, `...`, `x_{i+j}`.
* **Label (left, above tokens):** "input embedding"
* **Elements:** Corresponding yellow rounded rectangles (embeddings) above each input token.
* **Processing & Output Layer (Top):**
* **Label (left):** "last hidden state"
* **Elements:** A sequence of purple rounded rectangles (hidden states) emerging from the top of the LLM block.
* **Label (left, above hidden states):** "output token (sampling)"
* **Elements:** Tokens `x_i`, `x_{i+1}`, `x_{i+2}`, `...`, `x_{i+j}` and finally `[Answer]` are shown above the hidden states, with upward arrows indicating they are sampled from them.
* **Flow:** Arrows show a sequential, auto-regressive process. The output token `x_i` is fed back as the next input token, creating a loop. The final output is `[Answer]`.
**Right Panel: Chain of Continuous Thought (Coconut)**
* **Title:** "Chain of Continuous Thought (Coconut)" at the top. The word "Continuous" is highlighted in orange.
* **Subtitle/Annotation:** "Last hidden states are used as input embeddings" is written below the title.
* **Central Component:** A large, grey, rounded rectangle labeled "Large Language Model".
* **Input Layer (Bottom):**
* **Elements:** A sequence starting with `[Question]`, followed by a special token `<bot>` (beginning of thought), then a series of orange-to-purple gradient rounded rectangles, and ending with a special token `<eot>` (end of thought).
* **Flow:** Arrows show that the hidden state from one step is directly used as the input embedding for the next step, creating a continuous chain within the model's latent space.
* **Processing & Output Layer (Top):**
* **Elements:** A series of orange-to-purple gradient rounded rectangles (continuous thought states) emerge from the top of the LLM block.
* **Final Output:** A single purple hidden state leads to the final output token `[Answer]`, indicated by an upward arrow.
* **Key Difference:** There is no intermediate sampling of discrete output tokens (`x_i`, `x_{i+1}`, etc.) during the reasoning chain. The process operates on continuous hidden states until the final answer is generated.
### Detailed Analysis
**Chain-of-Thought (CoT) Process Flow:**
1. The model receives an initial `[Question]` token.
2. It generates a sequence of intermediate reasoning tokens (`x_i`, `x_{i+1}`, `x_{i+2}`...).
3. Each generated token is explicitly sampled (converted from a hidden state to a discrete token) and then fed back as the next input.
4. This creates a visible, discrete chain of "thought" tokens before the final `[Answer]` is produced.
**Chain of Continuous Thought (Coconut) Process Flow:**
1. The model receives an initial `[Question]` token and a special `<bot>` token.
2. Instead of generating discrete tokens, the model's last hidden state from one step is directly used as the input embedding for the next step.
3. This forms a chain of continuous thought states (represented by gradient-colored blocks) within the model's internal representation space.
4. After a series of these continuous steps, signaled by an `<eot>` token, the model produces the final `[Answer]`.
### Key Observations
1. **Discrete vs. Continuous:** The core distinction is that CoT reasons using a sequence of discrete, sampled tokens, while Coconut reasons using a sequence of continuous hidden state vectors.
2. **Special Tokens:** Coconut introduces explicit control tokens (`<bot>`, `<eot>`) to manage the continuous reasoning process, which are absent in the standard CoT diagram.
3. **Feedback Loop:** CoT has an explicit external feedback loop (output token becomes next input). Coconut's feedback loop is internal, passing hidden states directly.
4. **Visual Coding:** Color is used meaningfully. CoT uses solid yellow (input embeddings) and solid purple (hidden states). Coconut uses a yellow-to-orange-to-purple gradient for its continuous thought states, visually representing the transformation of information.
### Interpretation
This diagram illustrates a fundamental shift in how an LLM can perform multi-step reasoning.
* **What it suggests:** The Coconut method proposes that forcing a model to generate discrete language tokens for every reasoning step (as in CoT) may be a bottleneck or an unnecessary constraint. By allowing the model to reason in its native, continuous hidden state space, it might achieve more efficient, flexible, or powerful reasoning.
* **Relationship between elements:** The diagram positions Coconut as an evolution or alternative to CoT. Both start with a question and end with an answer, but the "black box" of intermediate reasoning is handled differently. CoT's process is transparent but rigid (tied to vocabulary), while Coconut's is opaque (continuous vectors) but potentially more fluid.
* **Notable implications:** The use of `<bot>` and `<eot>` tokens suggests the continuous reasoning process has a defined start and stop point, which is crucial for control. The absence of intermediate text output in Coconut implies the reasoning process is not directly interpretable to humans in real-time, which is a trade-off between potential performance and explainability. This diagram is likely from a research paper proposing the Coconut method, arguing that moving the reasoning chain from the discrete token space to the continuous latent space of the model is a promising direction for improving LLM capabilities.
DECODING INTELLIGENCE...