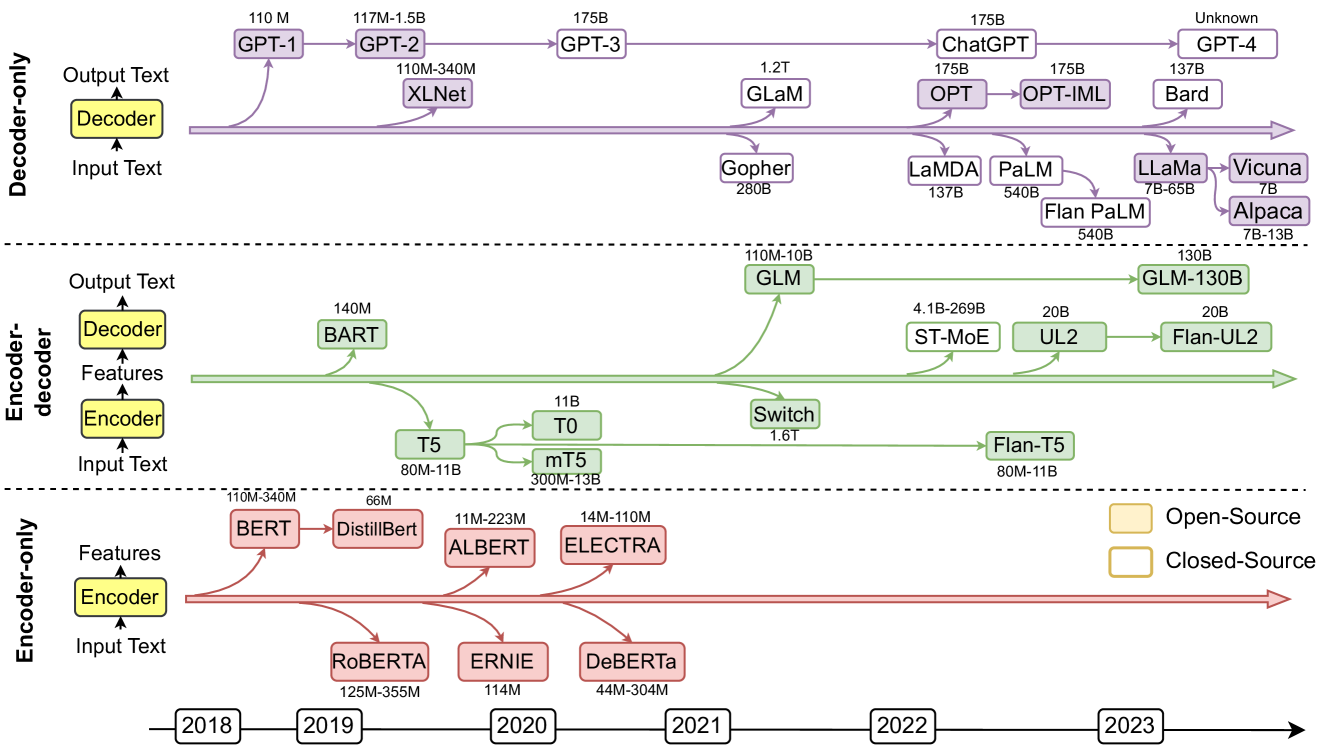
## Diagram: Timeline of Large Language Model Architectures and Evolution (2018-2023)
### Overview
This image is a technical timeline diagram illustrating the evolution and relationships of major Large Language Models (LLMs) from 2018 to 2023. It categorizes models into three primary architectural families: **Decoder-only**, **Encoder-decoder**, and **Encoder-only**. The diagram shows model names, their approximate parameter counts, and their lineage or influence via connecting arrows. A legend distinguishes between Open-Source and Closed-Source models.
### Components/Axes
1. **Main Sections (Vertical Division):**
* **Top Section:** Labeled **"Decoder-only"** on the left. Contains a simplified architecture diagram: `Input Text` -> `Decoder` -> `Output Text`.
* **Middle Section:** Labeled **"Encoder-decoder"** on the left. Contains a simplified architecture diagram: `Input Text` -> `Encoder` -> `Features` -> `Decoder` -> `Output Text`.
* **Bottom Section:** Labeled **"Encoder-only"** on the left. Contains a simplified architecture diagram: `Input Text` -> `Encoder` -> `Features`.
2. **Timeline (Horizontal Axis):**
* Located at the very bottom of the diagram.
* Marked with years in boxes: `2018`, `2019`, `2020`, `2021`, `2022`, `2023`.
* A red arrow extends from left to right, indicating chronological progression.
3. **Legend:**
* Positioned in the **bottom-right corner** of the main chart area.
* **Yellow-filled box:** `Open-Source`
* **White box with yellow border:** `Closed-Source`
4. **Model Nodes & Connections:**
* Models are represented as colored boxes (purple for Decoder-only, green for Encoder-decoder, red for Encoder-only).
* Each box contains the model name and its approximate parameter count (e.g., `GPT-3 175B`).
* Arrows connect models to show derivation, inspiration, or evolutionary path.
### Detailed Analysis
#### **Decoder-only Section (Purple)**
* **Trend:** Shows a clear progression towards models with vastly increasing parameter counts over time.
* **Models & Timeline Placement (Approximate):**
* **2018:** `GPT-1` (110M)
* **2019:** `GPT-2` (117M-1.5B), `XLNet` (110M-340M)
* **2020:** `GPT-3` (175B), `Gopher` (280B)
* **2021:** `GLaM` (1.2T), `LaMDA` (137B), `PaLM` (540B)
* **2022:** `ChatGPT` (175B), `OPT` (175B) -> `OPT-IML` (175B), `Flan PaLM` (540B), `LLaMa` (7B-65B)
* **2023:** `GPT-4` (Unknown), `Bard` (137B), `Vicuna` (7B), `Alpaca` (7B-13B)
* **Key Connections:** `GPT-1` -> `GPT-2` -> `GPT-3` -> `ChatGPT` -> `GPT-4`. `PaLM` leads to `Flan PaLM` and influences `LLaMa`, which in turn leads to `Vicuna` and `Alpaca`.
#### **Encoder-decoder Section (Green)**
* **Trend:** Shows branching evolution from foundational models like T5 and BART.
* **Models & Timeline Placement (Approximate):**
* **2019:** `BART` (140M), `T5` (80M-11B)
* **2020:** `T0` (11B), `mT5` (300M-13B)
* **2021:** `GLM` (110M-10B), `Switch` (1.6T)
* **2022:** `ST-MoE` (4.1B-269B), `UL2` (20B), `Flan-T5` (80M-11B), `GLM-130B` (130B)
* **2023:** `Flan-UL2` (20B)
* **Key Connections:** `T5` is a central node, leading to `T0`, `mT5`, and `Flan-T5`. `GLM` appears as a separate branch.
#### **Encoder-only Section (Red)**
* **Trend:** Focus on feature extraction models, with parameter sizes generally smaller than later decoder-only models.
* **Models & Timeline Placement (Approximate):**
* **2018:** `BERT` (110M-340M)
* **2019:** `DistillBert` (66M), `RoBERTa` (125M-355M)
* **2020:** `ALBERT` (11M-223M), `ERNIE` (114M), `ELECTRA` (14M-110M), `DeBERTa` (44M-304M)
* **Key Connections:** `BERT` is the foundational model, leading to `DistillBert`, `RoBERTa`, `ALBERT`, and `ELECTRA`.
### Key Observations
1. **Architectural Shift:** The diagram visually emphasizes the recent dominance and scale of **Decoder-only** models (e.g., GPT series, PaLM) compared to the other architectures, especially from 2021 onwards.
2. **Parameter Scale Explosion:** There is a clear trend of rapidly increasing model sizes, from millions (M) in 2018-2019 to hundreds of billions (B) and even trillions (T) of parameters by 2021-2022 (e.g., `GLaM` 1.2T, `Switch` 1.6T).
3. **Open vs. Closed Source:** The legend indicates a mix. Foundational models like `BERT`, `T5`, and `LLaMa` are open-source, while many of the largest and most prominent models like `GPT-3/4`, `ChatGPT`, `PaLM`, and `Bard` are closed-source.
4. **Fine-tuning & Derivatives:** The diagram highlights the trend of creating instruction-tuned or derivative versions of base models (e.g., `T5` -> `Flan-T5`, `PaLM` -> `Flan PaLM`, `UL2` -> `Flan-UL2`, `LLaMa` -> `Vicuna`/`Alpaca`).
### Interpretation
This diagram serves as a **genealogy of modern LLMs**, mapping their technical lineage and the rapid pace of development in the field. It demonstrates that the field has largely converged on the decoder-only transformer architecture for generating text, as exemplified by the GPT series and its successors. The explosive growth in parameter count suggests a prevailing research hypothesis that scale is a primary driver of capability. The presence of both open and closed-source models illustrates a dual ecosystem: closed models pushing the absolute frontier of scale and capability, while open models foster reproducibility, accessibility, and community-driven innovation (e.g., the `LLaMa` -> `Alpaca`/`Vicuna` branch). The timeline underscores that significant architectural diversification (Encoder-only, Encoder-decoder) occurred earlier (2018-2020), while the most recent years (2021-2023) are characterized by scaling and refining the decoder-only paradigm.