## Line Charts: Image-Caption vs. Interleaved Task Performance
### Overview
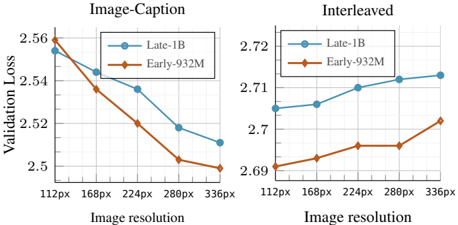
The image contains two side-by-side line charts comparing the validation loss of two models ("Late-1B" and "Early-932M") across increasing image resolutions. The left chart is for an "Image-Caption" task, and the right chart is for an "Interleaved" task. Both charts share the same x-axis (Image resolution) but have different y-axis scales for Validation Loss.
### Components/Axes
* **Chart Titles:**
* Left Chart: "Image-Caption"
* Right Chart: "Interleaved"
* **X-Axis (Both Charts):**
* Label: "Image resolution"
* Tick Labels (from left to right): "112px", "168px", "224px", "288px", "336px"
* **Y-Axis (Both Charts):**
* Label: "Validation Loss"
* Left Chart Scale: Ranges from 2.5 to 2.56, with major ticks at 2.5, 2.52, 2.54, 2.56.
* Right Chart Scale: Ranges from 2.69 to 2.72, with major ticks at 2.69, 2.7, 2.71, 2.72.
* **Legend (Both Charts, positioned top-left within the plot area):**
* Blue line with circle markers: "Late-1B"
* Orange line with diamond markers: "Early-932M"
### Detailed Analysis
**Left Chart: Image-Caption Task**
* **Trend Verification:** Both model lines show a clear downward trend, indicating that validation loss decreases as image resolution increases.
* **Data Series - Late-1B (Blue, Circles):**
* 112px: ~2.555
* 168px: ~2.545
* 224px: ~2.535
* 288px: ~2.520
* 336px: ~2.510
* **Data Series - Early-932M (Orange, Diamonds):**
* 112px: ~2.560
* 168px: ~2.535
* 224px: ~2.520
* 288px: ~2.505
* 336px: ~2.500
* **Comparison:** The Early-932M model consistently achieves a lower validation loss than the Late-1B model at every resolution point for this task. The gap between them appears relatively consistent.
**Right Chart: Interleaved Task**
* **Trend Verification:** Both model lines show a clear upward trend, indicating that validation loss increases as image resolution increases.
* **Data Series - Late-1B (Blue, Circles):**
* 112px: ~2.705
* 168px: ~2.707
* 224px: ~2.710
* 288px: ~2.712
* 336px: ~2.713
* **Data Series - Early-932M (Orange, Diamonds):**
* 112px: ~2.692
* 168px: ~2.695
* 224px: ~2.697
* 288px: ~2.697
* 336px: ~2.702
* **Comparison:** The Early-932M model again achieves a lower validation loss than the Late-1B model at every resolution point. The rate of increase (slope) for the Late-1B model appears slightly steeper than for the Early-932M model.
### Key Observations
1. **Divergent Trends:** The most striking observation is the opposite relationship between image resolution and validation loss for the two tasks. Higher resolution is beneficial for the Image-Caption task but detrimental for the Interleaved task.
2. **Consistent Model Performance:** The Early-932M model outperforms the Late-1B model (lower loss) across all tested resolutions and both tasks.
3. **Scale Difference:** The absolute validation loss values are significantly higher for the Interleaved task (2.69-2.72) compared to the Image-Caption task (2.50-2.56), suggesting the Interleaved task is inherently more challenging for these models.
4. **Performance Gap:** The performance gap between the two models is more pronounced in the Image-Caption task (a difference of ~0.01-0.02 loss points) than in the Interleaved task (a difference of ~0.01-0.013 loss points).
### Interpretation
This data suggests a fundamental difference in how these models process information for the two tasks. For the **Image-Caption** task, which likely involves generating a single descriptive text from an image, higher-resolution inputs provide richer visual detail, leading to more accurate captions and lower loss. The models benefit from the increased information.
Conversely, for the **Interleaved** task—which may involve processing sequences of images and text in a conversational or multi-turn format—higher resolution appears to be a hindrance. This could be due to several factors: the models may struggle with the increased computational complexity and noise from high-resolution images in a sequential context, or the task may rely more on high-level semantic understanding where fine-grained visual detail is less important or even distracting. The consistent superiority of the Early-932M model suggests its architecture or training is better optimized for both types of visual-linguistic tasks, though the reason for its relative robustness to the negative effect of high resolution in the Interleaved task would require further investigation. The charts provide clear evidence that input preprocessing (like resolution selection) must be task-specific.