\n
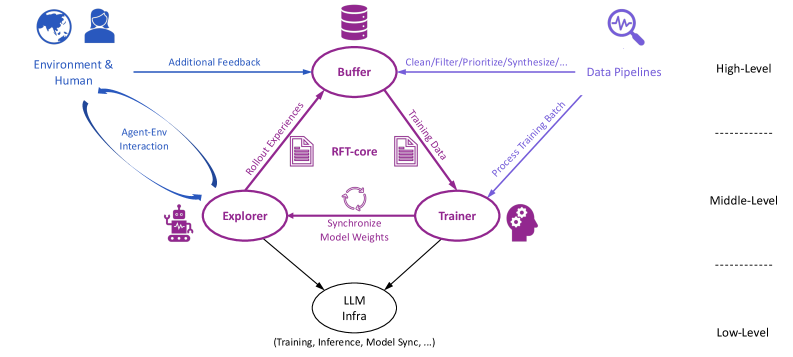
## Diagram: Reinforcement Learning from Tool-use (RFT) Core System
### Overview
The image depicts a diagram of a Reinforcement Learning from Tool-use (RFT) core system. It illustrates the interaction between an environment, a human, an agent, and various components involved in training and utilizing a Large Language Model (LLM). The diagram is structured into three levels: High-Level, Middle-Level, and Low-Level, indicating the abstraction of the processes.
### Components/Axes
The diagram consists of the following components:
* **Environment & Human:** Represented by a head-and-shoulders icon, providing "Additional Feedback".
* **Buffer:** A cylindrical shape, labeled "Buffer".
* **Data Pipelines:** Represented by a stethoscope icon, labeled "Data Pipelines".
* **RFT-core:** A central hexagonal shape, labeled "RFT-core".
* **Explorer:** A robot icon, labeled "Explorer".
* **Trainer:** A gear icon, labeled "Trainer".
* **LLM Infra:** A cloud icon, labeled "LLM Infra".
* **Agent-Env Interaction:** A curved arrow indicating interaction between the agent and the environment.
* **Rollout Experiences:** An arrow from Explorer to Buffer, labeled "Rollout Experiences".
* **Training Data:** An arrow from RFT-core to Trainer, labeled "Training Data".
* **Process Training Batch:** An arrow from Trainer to LLM Infra, labeled "Process Training Batch".
* **Clean/Filter/Prioritize/Synthesize...:** An arrow from Buffer to Data Pipelines, labeled "Clean/Filter/Prioritize/Synthesize...".
* **Synchronize Model Weights:** A bidirectional arrow between Explorer and Trainer, labeled "Synchronize Model Weights".
* **High-Level, Middle-Level, Low-Level:** Labels indicating the hierarchical structure of the system.
* **(Training, Inference, Model Sync, ...):** Text below LLM Infra, describing its functions.
### Detailed Analysis or Content Details
The diagram shows a cyclical flow of information.
1. The **Environment & Human** provide "Additional Feedback" to the **Buffer**.
2. The **Buffer** processes this feedback via "Clean/Filter/Prioritize/Synthesize..." and sends it to **Data Pipelines**.
3. The **Explorer** interacts with the **Environment**, generating "Rollout Experiences" which are sent to the **RFT-core**.
4. The **RFT-core** generates "Training Data" for the **Trainer**.
5. The **Trainer** processes this data into a "Process Training Batch" and sends it to the **LLM Infra**.
6. The **LLM Infra** handles "Training, Inference, Model Sync..." and provides updated model weights.
7. The **Explorer** and **Trainer** synchronize their model weights.
The diagram is vertically divided into three levels:
* **High-Level:** Contains the **Environment & Human** and **Data Pipelines**.
* **Middle-Level:** Contains the **Buffer**, **RFT-core**, **Explorer**, and **Trainer**.
* **Low-Level:** Contains the **LLM Infra**.
The arrows indicate the direction of data flow and interaction between the components. The arrows are colored as follows:
* Blue: Feedback from Environment & Human to Buffer.
* Red: Rollout Experiences from Explorer to RFT-core.
* Green: Training Data from RFT-core to Trainer.
* Orange: Process Training Batch from Trainer to LLM Infra.
* Purple: Synchronize Model Weights between Explorer and Trainer.
### Key Observations
The diagram emphasizes the iterative nature of reinforcement learning, with continuous feedback loops between the environment, agent, and LLM infrastructure. The hierarchical structure suggests a modular design, where each level performs specific functions. The RFT-core appears to be a central component, coordinating the flow of data between the different parts of the system.
### Interpretation
This diagram illustrates a system for reinforcement learning that leverages the capabilities of Large Language Models (LLMs). The RFT-core acts as the central hub, managing the interaction between an agent exploring an environment, a human providing feedback, and the LLM infrastructure responsible for training and inference. The system is designed to continuously improve the agent's performance through iterative feedback loops and model synchronization. The three-level structure suggests a separation of concerns, allowing for modularity and scalability. The inclusion of human feedback indicates a potential for incorporating human knowledge and guidance into the learning process. The diagram highlights the importance of data processing and synthesis in preparing data for training the LLM. The system appears to be designed for complex tasks that require both exploration and learning from experience. The bidirectional arrow between the Explorer and Trainer suggests a continuous refinement of the model weights based on the agent's interactions with the environment.