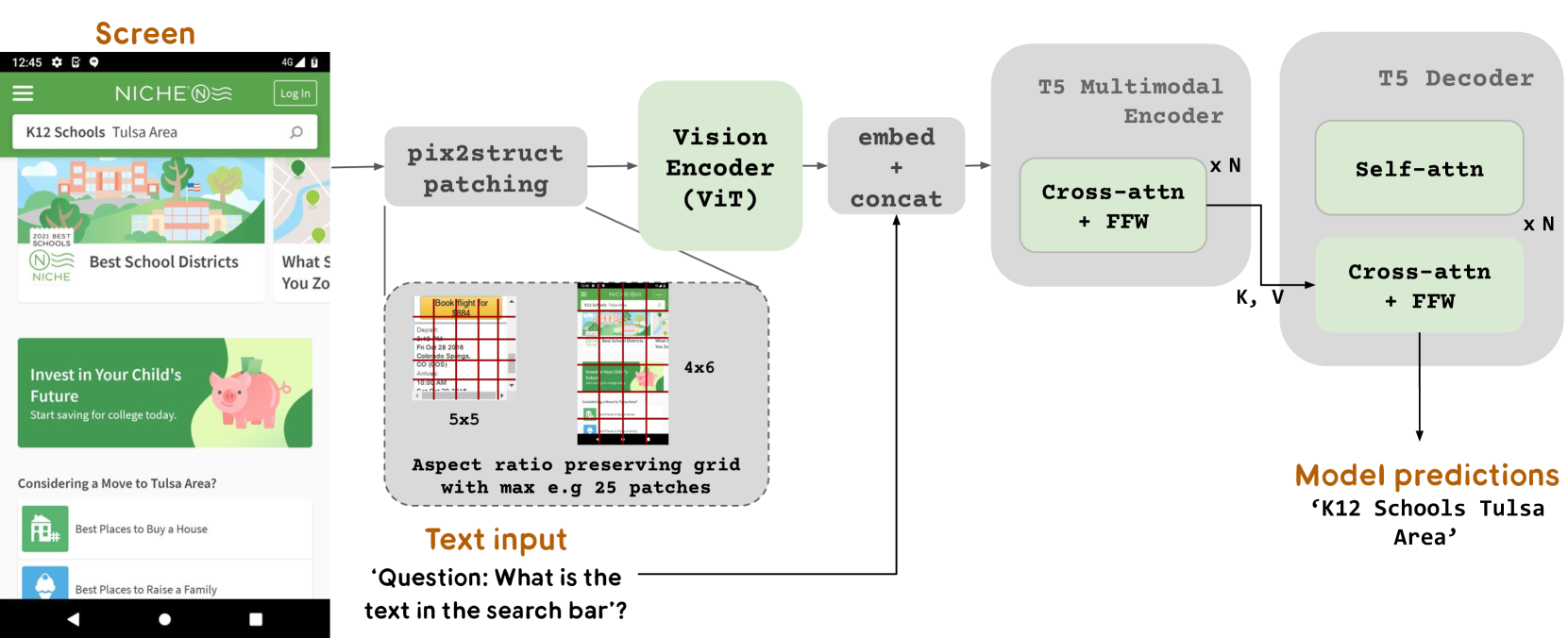
# Technical Document Extraction: Multimodal Model Architecture
This image illustrates a technical pipeline for a multimodal machine learning model designed to process visual screen data and text queries to generate predictions.
## 1. Input Components
### Screen (Visual Input)
The leftmost component is a mobile application screenshot for "NICHE".
* **Header:** Contains a hamburger menu, the "NICHE" logo, and a "Log In" button.
* **Search Bar:** Contains the text "K12 Schools Tulsa Area".
* **Content Cards:**
* "Best School Districts" with a 2021 Best Schools badge.
* "Invest in Your Child's Future" with a piggy bank illustration.
* List items: "Best Places to Buy a House" and "Best Places to Raise a Family".
### Text Input
Located at the bottom center, providing context for the model.
* **Content:** `'Question: What is the text in the search bar?'`
---
## 2. Processing Pipeline (Flow)
### Step 1: pix2struct patching
The screen image is passed into a patching module.
* **Mechanism:** The image is divided into an "Aspect ratio preserving grid with max e.g 25 patches".
* **Sub-visuals:**
* A **5x5** grid example showing a flight booking interface.
* A **4x6** grid example showing the NICHE mobile screen divided into green-tinted rectangular patches.
### Step 2: Vision Encoder (ViT)
The patched image data flows into a **Vision Encoder (ViT)**, represented by a light green block.
### Step 3: embed + concat
The output from the Vision Encoder and the **Text input** are merged in this stage.
* The text query is embedded and concatenated with the visual embeddings.
### Step 4: T5 Multimodal Encoder
The concatenated data enters a grey block labeled **T5 Multimodal Encoder**.
* **Internal Component:** **Cross-attn + FFW** (Cross-attention and Feed-Forward Network).
* **Repetition:** This block is repeated **x N** times.
* **Output:** Key (**K**) and Value (**V**) vectors are passed to the next stage.
### Step 5: T5 Decoder
A large grey block representing the decoding phase.
* **Internal Components:**
1. **Self-attn** (Self-attention)
2. **Cross-attn + FFW** (Cross-attention and Feed-Forward Network)
* **Repetition:** This sequence is repeated **x N** times.
---
## 3. Output
### Model predictions
The final output generated by the T5 Decoder.
* **Result:** `'K12 Schools Tulsa Area'`
* **Logic Check:** This correctly answers the input question by extracting the specific text found in the search bar of the original screen image.