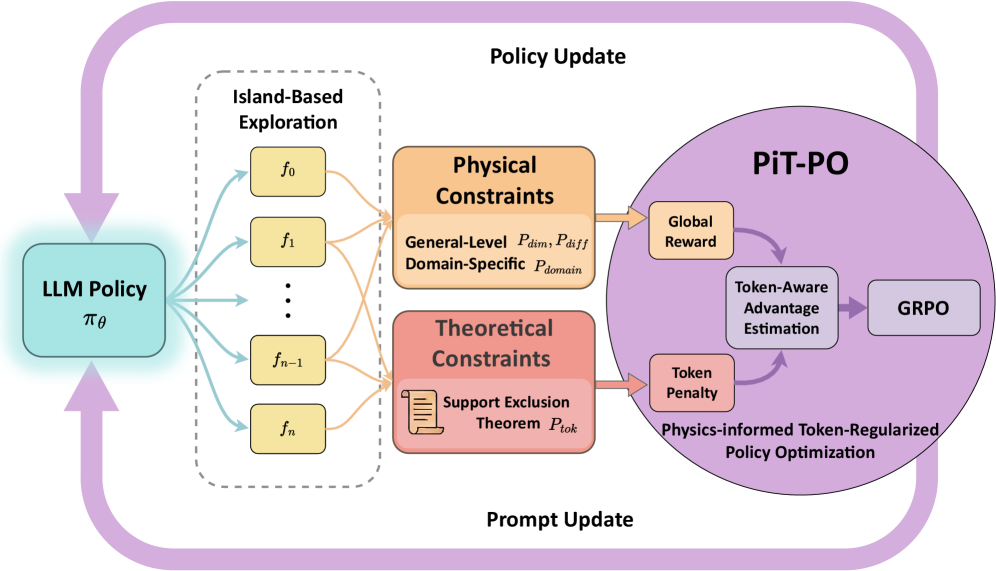
## Diagram: PiT-PO Framework
### Overview
The image presents a diagram of the Physics-informed Token-Regularized Policy Optimization (PiT-PO) framework. It illustrates the interaction between an LLM Policy, Island-Based Exploration, Physical and Theoretical Constraints, and the PiT-PO module itself, showing how these components contribute to policy and prompt updates.
### Components/Axes
* **LLM Policy:** Represented by a light blue rounded rectangle labeled "LLM Policy" with the notation "πθ" below it. Located on the left side of the diagram.
* **Island-Based Exploration:** Enclosed in a dashed gray rounded rectangle. Contains multiple yellow rounded rectangles labeled "f0", "f1", ..., "fn-1", "fn".
* **Physical Constraints:** An orange rounded rectangle labeled "Physical Constraints". Sub-labels include "General-Level Pdim, Pdiff" and "Domain-Specific Pdomain".
* **Theoretical Constraints:** A red rounded rectangle labeled "Theoretical Constraints". Contains a document icon and the sub-label "Support Exclusion Theorem Ptok".
* **PiT-PO:** A large purple circle containing several components:
* "Global Reward" (orange rounded rectangle)
* "Token-Aware Advantage Estimation" (gray rounded rectangle)
* "GRPO" (gray rounded rectangle)
* "Token Penalty" (red rounded rectangle)
* "Physics-informed Token-Regularized Policy Optimization" (text label at the bottom of the circle)
* **Policy Update:** Text label at the top of the diagram.
* **Prompt Update:** Text label at the bottom of the diagram.
### Detailed Analysis
* **Flow:**
* The LLM Policy (πθ) sends outputs (represented by light blue arrows) to the Island-Based Exploration module.
* The Island-Based Exploration module sends outputs (represented by orange arrows) to both the Physical Constraints and Theoretical Constraints modules.
* The Physical and Theoretical Constraints modules send outputs (represented by orange arrows) to the PiT-PO module's "Global Reward" and "Token Penalty" components, respectively.
* Within the PiT-PO module, there is a feedback loop between "Token-Aware Advantage Estimation" and "Token Penalty" (represented by purple arrows).
* "Token-Aware Advantage Estimation" sends output (represented by a purple arrow) to "GRPO".
* The PiT-PO module sends feedback (represented by a purple arrow) back to the LLM Policy (πθ), completing the loop.
* A large purple arrow loops from the PiT-PO module back to the LLM Policy, labeled "Prompt Update".
* A large purple arrow loops from the LLM Policy to the Physical and Theoretical Constraints, labeled "Policy Update".
* **Island-Based Exploration Details:**
* The Island-Based Exploration module contains multiple "f" nodes, indexed from 0 to n.
* **Constraint Details:**
* Physical Constraints are divided into General-Level (Pdim, Pdiff) and Domain-Specific (Pdomain) constraints.
* Theoretical Constraints are based on the Support Exclusion Theorem (Ptok).
### Key Observations
* The diagram illustrates a closed-loop system where the LLM Policy is updated based on feedback from the PiT-PO module, which incorporates physical and theoretical constraints.
* The Island-Based Exploration module seems to provide diverse inputs to the constraint modules.
* The PiT-PO module uses a token-aware approach, incorporating both global rewards and token penalties.
### Interpretation
The diagram describes the PiT-PO framework, which aims to improve LLM policies by incorporating physical and theoretical constraints during the optimization process. The Island-Based Exploration module likely serves to generate a diverse set of candidate policies, which are then evaluated against the constraints. The PiT-PO module uses a token-aware approach, suggesting that it considers the impact of individual tokens on the overall policy performance. The feedback loop ensures that the LLM policy is continuously refined based on the constraints and rewards. The "Prompt Update" and "Policy Update" arrows indicate that both the prompt and the policy of the LLM are being updated during the process. This framework appears to be designed to create more robust and reliable LLM policies by grounding them in real-world constraints and physics-based principles.