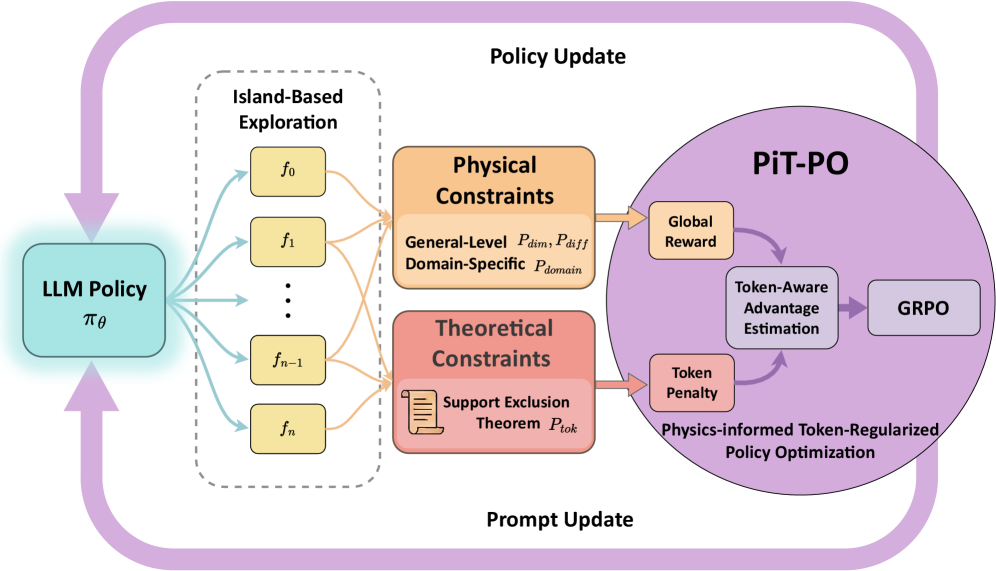
## System Architecture Diagram: Physics-informed Token-Regularized Policy Optimization (PiT-PO)
### Overview
The image is a technical system architecture diagram illustrating a reinforcement learning or policy optimization framework named **PiT-PO** (Physics-informed Token-Regularized Policy Optimization). The diagram depicts a cyclical process where an LLM Policy is updated through a multi-stage exploration and constraint-based optimization loop. The primary language of the diagram is English, with mathematical notation.
### Components/Axes
The diagram is organized into several interconnected blocks and regions, flowing from left to right and looping back.
**1. Left Region: Policy Source**
* **Component:** A teal-colored rounded rectangle labeled **"LLM Policy"** with the mathematical symbol **π_θ** below it.
* **Position:** Far left, centered vertically.
* **Function:** Serves as the starting point and the entity being updated.
**2. Center-Left Region: Exploration Module**
* **Component:** A dashed-line box labeled **"Island-Based Exploration"**.
* **Contents:** Inside this box are five yellow rounded rectangles arranged vertically, labeled **f₀**, **f₁**, **...**, **fₙ₋₁**, **fₙ**.
* **Connections:** Multiple light blue arrows originate from the "LLM Policy" block and point to each of the `f` blocks. Orange arrows then flow from each `f` block to the right, towards the constraint modules.
**3. Center Region: Constraint Modules**
Two distinct, colored blocks receive input from the exploration module.
* **Top Block (Orange):** Labeled **"Physical Constraints"**.
* Sub-text: **"General-Level P_dim, P_diff"** and **"Domain-Specific P_domain"**.
* **Bottom Block (Red):** Labeled **"Theoretical Constraints"**.
* Contains an icon of a document and the text **"Support Exclusion Theorem P_tok"**.
* **Connections:** Both blocks have orange arrows pointing right, into the large "PiT-PO" circle.
**4. Right Region: Core Optimization Engine (PiT-PO)**
* **Component:** A large, light purple circle labeled **"PiT-PO"** at the top.
* **Sub-components within the circle:**
* **"Global Reward"** (small orange box, top-left inside circle).
* **"Token Penalty"** (small orange box, bottom-left inside circle).
* **"Token-Aware Advantage Estimation"** (central white box).
* **"GRPO"** (small purple box, right side).
* **Flow within PiT-PO:** Arrows show that "Global Reward" and "Token Penalty" feed into "Token-Aware Advantage Estimation," which then points to "GRPO".
* **Descriptive Text:** At the bottom of the circle: **"Physics-informed Token-Regularized Policy Optimization"**.
**5. Feedback Loops (Outer Cycle)**
* **Top Arrow:** A large, purple, curved arrow labeled **"Policy Update"** flows from the top of the "PiT-PO" circle back to the top of the "LLM Policy" block.
* **Bottom Arrow:** A large, purple, curved arrow labeled **"Prompt Update"** flows from the bottom of the "PiT-PO" circle back to the bottom of the "LLM Policy" block.
### Detailed Analysis
The diagram outlines a closed-loop training or optimization process:
1. **Initialization:** The process starts with an **LLM Policy (π_θ)**.
2. **Exploration:** The policy generates multiple exploration paths or functions (`f₀` to `fₙ`) via the **Island-Based Exploration** module.
3. **Constraint Application:** The outputs of exploration are evaluated against two sets of constraints:
* **Physical Constraints:** These include general-level constraints (`P_dim`, `P_diff`) and domain-specific constraints (`P_domain`).
* **Theoretical Constraints:** Specifically, a constraint derived from the **Support Exclusion Theorem (`P_tok`)**.
4. **Optimization (PiT-PO):** The constrained outputs enter the **PiT-PO** engine. Here:
* A **Global Reward** signal and a **Token Penalty** are computed.
* These are used for **Token-Aware Advantage Estimation**.
* The estimation informs the **GRPO** (likely an acronym for a specific policy optimization algorithm, e.g., Generalized Reward Policy Optimization).
5. **Update:** The optimization results are used to perform two updates on the original LLM Policy:
* A **Policy Update** (top loop).
* A **Prompt Update** (bottom loop).
### Key Observations
* **Dual Constraint Types:** The system explicitly separates and incorporates both *physical* and *theoretical* constraints, suggesting a hybrid approach to guide policy learning.
* **Token-Level Regularization:** The inclusion of "Token Penalty" and "Token-Aware Advantage Estimation" indicates the optimization operates at the granularity of individual tokens, not just high-level rewards.
* **Parallel Exploration:** The "Island-Based Exploration" with multiple `f` functions suggests a population-based or parallel sampling strategy to explore the solution space.
* **Dual Update Mechanism:** The policy is updated via two distinct pathways ("Policy Update" and "Prompt Update"), implying that both the model parameters and the input prompts are being optimized.
### Interpretation
This diagram represents a sophisticated reinforcement learning framework designed to train or fine-tune a Large Language Model (LLM). The core innovation appears to be the **PiT-PO** method, which integrates physics-based and theoretical constraints directly into the policy optimization process.
The system's goal is to produce an LLM policy (`π_θ`) that is not only reward-optimized but also adheres to predefined physical laws and theoretical boundaries. The "Island-Based Exploration" likely ensures diverse candidate solutions are generated. The constraints (`P_dim`, `P_diff`, `P_domain`, `P_tok`) act as filters or regularizers, preventing the policy from exploring invalid or nonsensical regions of the solution space. The final "Token-Regularized" step ensures the model's outputs are coherent and constrained at the fundamental token level.
In essence, this is a blueprint for creating more reliable, physically plausible, and theoretically sound LLM behaviors by embedding domain knowledge directly into the reinforcement learning loop. The dual update mechanism (policy and prompt) suggests a holistic approach to optimization, refining both the model's internal reasoning and its interaction with input stimuli.