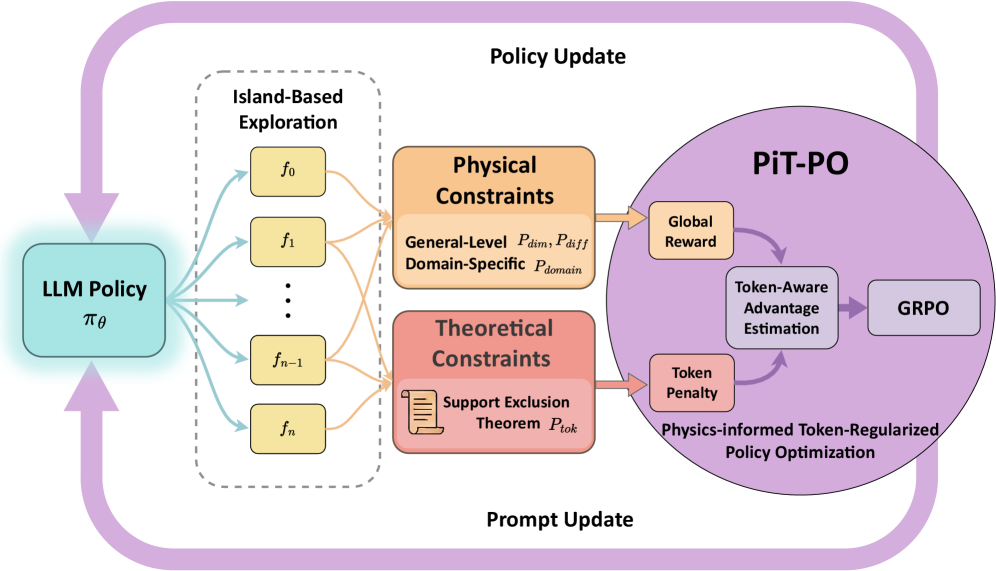
## Diagram: Process Flow for Physics-Informed Token-Regularized Policy Optimization
### Overview
The diagram illustrates a cyclical process for optimizing a Language Model (LLM) policy through island-based exploration, constraint integration, and physics-informed token-regularized policy optimization (PiT-PO). Arrows indicate directional flow between components, emphasizing iterative updates.
---
### Components/Axes
1. **Left Section (Island-Based Exploration)**
- **Box**: "Island-Based Exploration"
- Sub-components: Functions `f₀`, `f₁`, ..., `fₙ` (representing exploration outputs).
- **Arrows**: Connect "LLM Policy" (`π_θ`) to exploration functions, indicating policy-driven exploration.
2. **Middle Section (Constraints)**
- **Box 1**: "Physical Constraints"
- Sub-components:
- General-Level: `P_dim`, `P_diff`
- Domain-Specific: `P_domain`
- **Box 2**: "Theoretical Constraints"
- Sub-component: "Support Exclusion Theorem" (`P_tok`).
- **Arrows**: Connect exploration outputs to constraints, showing constraint evaluation.
3. **Right Section (Policy Update)**
- **Circle**: "PiT-PO" (Physics-informed Token-Regularized Policy Optimization)
- Sub-components:
- "Token-Aware Advantage Estimation"
- "GRPO" (Gradient Regularized Policy Optimization)
- "Token Penalty"
- **Arrows**:
- From constraints to "Global Reward" and "Token Penalty."
- From "Token-Aware Advantage Estimation" to GRPO.
- From GRPO back to "LLM Policy" (`π_θ`), completing the loop.
---
### Detailed Analysis
- **LLM Policy (`π_θ`)**:
- Central node driving the process.
- Outputs exploration functions (`f₀` to `fₙ`) for island-based exploration.
- **Island-Based Exploration**:
- Generates diverse function outputs (`f₀` to `fₙ`) to explore policy behavior.
- **Physical Constraints**:
- Enforce general (`P_dim`, `P_diff`) and domain-specific (`P_domain`) rules.
- Ensure exploration outputs adhere to real-world physics.
- **Theoretical Constraints**:
- "Support Exclusion Theorem" (`P_tok`) filters invalid or redundant exploration paths.
- **PiT-PO System**:
- Integrates constraints into policy updates via:
1. **Token-Aware Advantage Estimation**: Evaluates policy performance with token-level awareness.
2. **GRPO**: Optimizes policy using gradient regularization.
3. **Token Penalty**: Penalizes deviations from physical/theoretical constraints.
- **Cyclical Flow**:
- Policy → Exploration → Constraints → Policy Update → Repeat.
---
### Key Observations
1. **Iterative Optimization**: The loop emphasizes continuous refinement of the LLM policy using constraint feedback.
2. **Constraint Integration**: Physical and theoretical constraints act as gatekeepers for valid exploration paths.
3. **Token-Aware Mechanisms**: Highlight the importance of token-level granularity in policy optimization.
4. **GRPO Role**: Serves as the final optimization step, balancing exploration and constraint adherence.
---
### Interpretation
This diagram represents a framework for training robust LLM policies in constrained environments. By combining island-based exploration (diverse function sampling) with physics and theoretical constraints, the system ensures policies remain grounded in real-world feasibility. The PiT-PO system further refines policies using token-aware advantage estimation and gradient regularization, preventing overfitting to exploration noise. The cyclical nature suggests a reinforcement learning approach where constraints dynamically shape policy updates, critical for applications like robotics or safety-critical systems.