## Stacked Bar Chart: Attention Distribution by Token Type Across Model Layers
### Overview
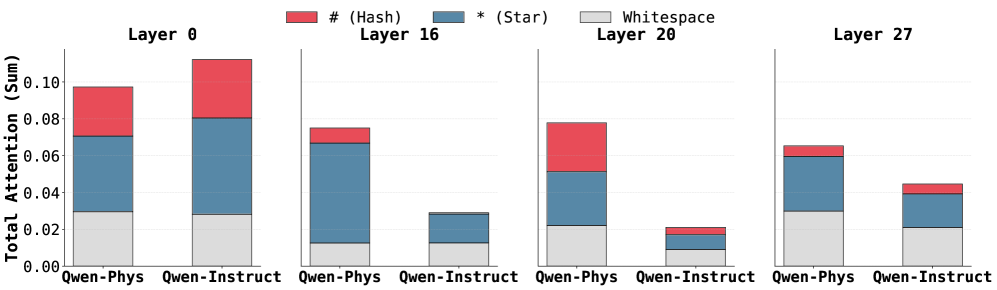
The image displays a stacked bar chart comparing the total attention sum allocated to three different token types (`#` (Hash), `*` (Star), and Whitespace) across four specific layers (0, 16, 20, 27) for two different models: "Qwen-Phys" and "Qwen-Instruct". The chart illustrates how the composition of attention changes between models and across network depth.
### Components/Axes
* **Chart Type:** Grouped, stacked bar chart.
* **Legend:** Positioned at the top center of the image.
* Red square: `# (Hash)`
* Blue square: `* (Star)`
* Gray square: `Whitespace`
* **Y-Axis:** Labeled "Total Attention (Sum)". The scale runs from 0.00 to 0.10, with major tick marks at 0.00, 0.02, 0.04, 0.06, 0.08, and 0.10.
* **X-Axis:** Grouped by layer number. Each layer group contains two bars, one for each model.
* **Layer 0:** Leftmost group. Bars for "Qwen-Phys" and "Qwen-Instruct".
* **Layer 16:** Second group from left. Bars for "Qwen-Phys" and "Qwen-Instruct".
* **Layer 20:** Third group from left. Bars for "Qwen-Phys" and "Qwen-Instruct".
* **Layer 27:** Rightmost group. Bars for "Qwen-Phys" and "Qwen-Instruct".
* **Bar Labels:** The model names "Qwen-Phys" and "Qwen-Instruct" are written below their respective bars within each layer group.
### Detailed Analysis
**Layer 0:**
* **Qwen-Phys:** Total height ~0.098. Composition (bottom to top): Whitespace ~0.030, Star (blue) ~0.042 (reaching ~0.072), Hash (red) ~0.026 (reaching ~0.098).
* **Qwen-Instruct:** Total height ~0.112 (the tallest bar in the chart). Composition: Whitespace ~0.029, Star ~0.051 (reaching ~0.080), Hash ~0.032 (reaching ~0.112).
* **Trend:** Both models show high total attention in the first layer. Qwen-Instruct allocates slightly more attention overall, with a notably larger Hash component.
**Layer 16:**
* **Qwen-Phys:** Total height ~0.075. Composition: Whitespace ~0.012, Star ~0.055 (reaching ~0.067), Hash ~0.008 (reaching ~0.075).
* **Qwen-Instruct:** Total height ~0.029. Composition: Whitespace ~0.012, Star ~0.017 (reaching ~0.029), Hash ~0.000 (no visible red segment).
* **Trend:** A significant drop in total attention for both models compared to Layer 0. The Hash component becomes very small or absent. Qwen-Phys maintains a much higher total attention than Qwen-Instruct at this layer.
**Layer 20:**
* **Qwen-Phys:** Total height ~0.079. Composition: Whitespace ~0.022, Star ~0.030 (reaching ~0.052), Hash ~0.027 (reaching ~0.079).
* **Qwen-Instruct:** Total height ~0.021. Composition: Whitespace ~0.002, Star ~0.011 (reaching ~0.013), Hash ~0.008 (reaching ~0.021).
* **Trend:** Qwen-Phys's total attention rebounds slightly from Layer 16, with a substantial Hash component reappearing. Qwen-Instruct's total attention continues to decrease, reaching its lowest point in the chart.
**Layer 27:**
* **Qwen-Phys:** Total height ~0.065. Composition: Whitespace ~0.030, Star ~0.030 (reaching ~0.060), Hash ~0.005 (reaching ~0.065).
* **Qwen-Instruct:** Total height ~0.045. Composition: Whitespace ~0.021, Star ~0.019 (reaching ~0.040), Hash ~0.005 (reaching ~0.045).
* **Trend:** Total attention for Qwen-Phys decreases from Layer 20. Qwen-Instruct shows an increase from its Layer 20 low. The Hash component is minimal for both models. Whitespace becomes a more significant portion of the total for both, especially for Qwen-Phys.
### Key Observations
1. **Model Disparity:** Qwen-Instruct has the single highest attention sum (Layer 0) but also the lowest (Layer 20), showing greater variance across layers. Qwen-Phys maintains a more consistent, higher baseline of attention in the middle layers (16, 20).
2. **Hash Token Attention:** The red `# (Hash)` segment is most prominent in Layer 0 for both models and in Layer 20 for Qwen-Phys. It is nearly absent in Layer 16 for both and minimal in Layer 27.
3. **Star Token Dominance:** The blue `* (Star)` segment is the largest or second-largest component in every bar, indicating it consistently receives a major share of attention.
4. **Whitespace Role:** The gray Whitespace component is a stable, non-trivial base layer of attention in all bars, typically ranging between 0.01 and 0.03.
5. **Layer-Specific Behavior:** Layer 0 is characterized by high total attention and significant Hash components. Middle layers (16, 20) show a divergence between the models. The final layer (27) shows a convergence in composition, with reduced Hash attention and increased relative Whitespace.
### Interpretation
This chart visualizes how two different training paradigms (Physics-focused vs. Instruct-tuned) affect the internal attention mechanisms of a language model across its depth.
* **Early Layer (0) Specialization:** Both models heavily attend to special tokens (`#` and `*`) at the input stage, suggesting these tokens act as crucial anchors or delimiters for initial processing. The higher attention in Qwen-Instruct may reflect a broader initial parsing strategy.
* **Mid-Layer Divergence:** The stark difference in Layers 16 and 20 suggests the models develop fundamentally different internal representations. Qwen-Phys maintains strong engagement with special tokens (especially `#` in Layer 20), possibly indicating ongoing structural or relational processing tied to its physics training. Qwen-Instruct's attention collapses in these layers, which could imply a shift towards processing semantic content rather than syntactic or structural markers.
* **Late-Layer Convergence:** By Layer 27, both models reduce focus on special tokens (`#` and `*`) and increase the relative share of attention to Whitespace. This may represent a final integration or "smoothing" phase before output generation, where the distinction between token types becomes less critical than the overall context.
* **Functional Implication:** The persistent, significant attention to the `* (Star)` token across all layers and both models is a key finding. It suggests this token plays a universally important role in the model's architecture, perhaps as a primary separator, a placeholder for unknown relations, or a key component in attention head specialization. The fluctuating role of the `# (Hash)` token appears more model- and layer-specific.