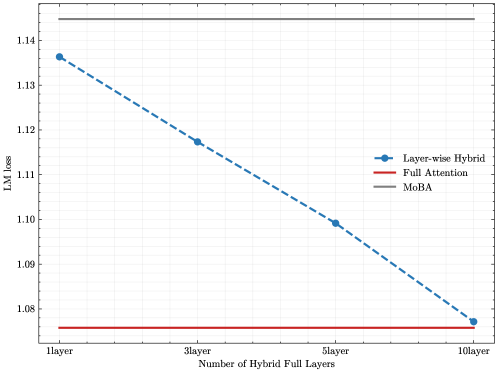
## Line Chart: LM Loss vs. Number of Hybrid Full Layers
### Overview
The image is a line chart comparing the Language Model (LM) loss for three different models: Layer-wise Hybrid, Full Attention, and MoBA, as the number of hybrid full layers increases. The x-axis represents the number of hybrid full layers (1, 3, 5, and 10), and the y-axis represents the LM loss.
### Components/Axes
* **X-axis:** "Number of Hybrid Full Layers" with markers at "1layer", "3layer", "5layer", and "10layer".
* **Y-axis:** "LM loss" with a numerical scale ranging from 1.08 to 1.14, with tick marks at each 0.01 increment.
* **Legend:** Located on the right side of the chart, it identifies the three models:
* Layer-wise Hybrid (blue line with circle markers)
* Full Attention (red line)
* MoBA (gray line)
### Detailed Analysis
* **Layer-wise Hybrid (blue, dashed line with circle markers):** The LM loss decreases as the number of hybrid full layers increases.
* 1 layer: approximately 1.137
* 3 layers: approximately 1.117
* 5 layers: approximately 1.099
* 10 layers: approximately 1.077
* **Full Attention (red, solid line):** The LM loss remains constant regardless of the number of hybrid full layers. The value is approximately 1.076.
* **MoBA (gray, solid line):** The LM loss remains constant regardless of the number of hybrid full layers. The value is approximately 1.147.
### Key Observations
* The Layer-wise Hybrid model shows a decreasing LM loss as the number of hybrid full layers increases, indicating improved performance.
* The Full Attention and MoBA models maintain a constant LM loss, suggesting that their performance is not affected by the number of hybrid full layers.
* The MoBA model has the highest LM loss, followed by the Layer-wise Hybrid model (at 1 layer), and the Full Attention model has the lowest LM loss.
### Interpretation
The chart suggests that increasing the number of hybrid full layers in the Layer-wise Hybrid model improves its performance, as indicated by the decreasing LM loss. The Full Attention model consistently outperforms the MoBA model, as it has a lower LM loss. The Full Attention and MoBA models are not affected by the number of hybrid full layers, implying that their architecture or training is independent of this parameter. The Layer-wise Hybrid model starts with a higher loss than Full Attention but approaches Full Attention's performance as the number of layers increases.