\n
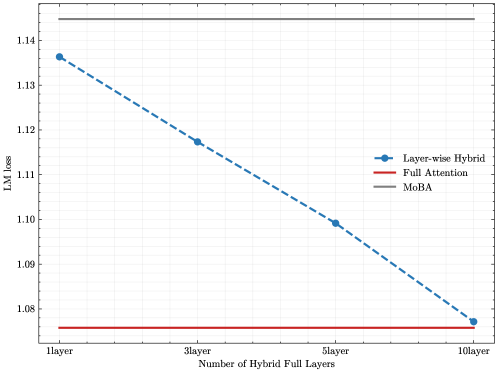
## Line Chart: LM Loss vs. Number of Hybrid Full Layers
### Overview
This image presents a line chart illustrating the relationship between the number of hybrid full layers and the LM (Language Model) loss for different attention mechanisms. Three attention mechanisms are compared: Layer-wise Hybrid, Full Attention, and MoBA.
### Components/Axes
* **X-axis:** Number of Hybrid Full Layers. Marked at 1 layer, 3 layer, 5 layer, and 10 layer.
* **Y-axis:** LM loss. Scale ranges from approximately 1.04 to 1.14.
* **Legend:** Located in the top-right corner.
* Layer-wise Hybrid (Blue line with diamond markers)
* Full Attention (Red line)
* MoBA (Brown line)
### Detailed Analysis
The chart displays three lines representing the LM loss for each attention mechanism as the number of hybrid full layers increases.
* **Layer-wise Hybrid (Blue):** The line slopes downward, indicating a decrease in LM loss as the number of layers increases.
* At 1 layer: Approximately 1.135 LM loss.
* At 3 layers: Approximately 1.12 LM loss.
* At 5 layers: Approximately 1.10 LM loss.
* At 10 layers: Approximately 1.07 LM loss.
* **Full Attention (Red):** This line is nearly horizontal, indicating a relatively constant LM loss regardless of the number of layers. The loss remains around 1.06.
* **MoBA (Brown):** This line is also nearly horizontal, maintaining a constant LM loss around 1.06.
### Key Observations
* The Layer-wise Hybrid attention mechanism demonstrates a significant reduction in LM loss as the number of layers increases.
* Both Full Attention and MoBA exhibit stable LM loss values, showing minimal change with varying layer counts.
* The Layer-wise Hybrid consistently has a higher LM loss than the other two methods at 1 layer, but eventually falls below them at 10 layers.
### Interpretation
The data suggests that increasing the number of hybrid full layers in the Layer-wise Hybrid attention mechanism leads to improved language modeling performance, as indicated by the decreasing LM loss. This implies that the model benefits from the increased capacity and complexity provided by additional layers. In contrast, the Full Attention and MoBA mechanisms appear to reach a performance plateau relatively quickly, with their LM loss remaining stable regardless of the number of layers. This could indicate that these mechanisms are already operating at their optimal performance level or that adding more layers does not provide significant additional benefits. The initial higher loss of the Layer-wise Hybrid could be due to the model needing more layers to fully realize its potential, or it could be a characteristic of the mechanism itself. The convergence of the Layer-wise Hybrid loss towards the other two methods at 10 layers suggests a potential point of diminishing returns.