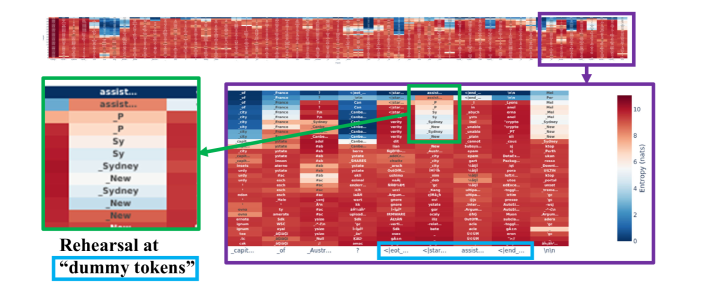
## Heatmap: Attention Entropy Visualization
### Overview
The image presents a heatmap visualizing attention entropy, likely from a language model or similar system. The heatmap displays attention weights between different tokens, with color intensity representing the entropy of the attention distribution. A smaller heatmap inset shows the attention weights for a specific set of tokens ("assist..."), and a zoomed-in section highlights a particular area of interest. The image also includes text annotations explaining the "Rehearsal at 'dummy tokens'" concept.
### Components/Axes
* **X-axis:** Represents tokens, labeled as "capt...", "Avst...", "<|eat|...", "<|star|...", "assist...", "<|end|...", "Win".
* **Y-axis:** Represents tokens, including "P", "Sy", "Sydney", "New", "New", "New", "France", "Canada", "Chile", "Color", "Sydney", "France", "Canada", "Chile", "Color".
* **Color Scale (Right):** Represents "Entropy (nats)", ranging from approximately 0 (blue) to 10 (red).
* **Inset Heatmap (Top-Left):** Displays attention weights for tokens labeled "assist...", with rows labeled "P", "Sy", "Sydney", "New", "New", "New".
* **Annotations:**
* "Rehearsal at 'dummy tokens'" - Located below the inset heatmap.
* Green arrows pointing from the inset heatmap to the main heatmap, and from the main heatmap to a zoomed-in section.
### Detailed Analysis or Content Details
The main heatmap shows attention entropy between the tokens listed on the X and Y axes. The color intensity indicates the entropy value.
* **Overall Trend:** The heatmap is predominantly red, indicating high entropy in most attention distributions. There are some areas of blue, indicating lower entropy.
* **X-axis Tokens:**
* "capt...": Shows a mix of red and blue, with some areas of moderate entropy.
* "Avst...": Similar to "capt...", with a mix of entropy levels.
* "<|eat|...": Predominantly red, indicating high entropy.
* "<|star|...": Predominantly red, indicating high entropy.
* "assist...": Shows a more varied pattern, with some blue and red areas.
* "<|end|...": Predominantly red, indicating high entropy.
* "Win": Predominantly red, indicating high entropy.
* **Y-axis Tokens:**
* "P": Shows a mix of red and blue, with some areas of moderate entropy.
* "Sy": Shows a mix of red and blue, with some areas of moderate entropy.
* "Sydney": Shows a mix of red and blue, with some areas of moderate entropy.
* "New": Shows a mix of red and blue, with some areas of moderate entropy.
* "France": Shows a mix of red and blue, with some areas of moderate entropy.
* "Canada": Shows a mix of red and blue, with some areas of moderate entropy.
* "Chile": Shows a mix of red and blue, with some areas of moderate entropy.
* "Color": Shows a mix of red and blue, with some areas of moderate entropy.
* **Inset Heatmap ("assist...")**:
* The inset heatmap shows attention weights between the tokens "P", "Sy", "Sydney", "New", "New", "New".
* The color intensity varies, with some areas of red and some of blue.
* The attention between "P" and "Sy" appears to be relatively high (red).
* The attention between "Sydney" and "New" appears to be relatively low (blue).
* **Zoomed-in Section:** The zoomed-in section highlights a specific area of the main heatmap, likely to show a more detailed view of the attention entropy in that region.
### Key Observations
* High entropy is prevalent across most token pairs, suggesting a diffuse attention distribution.
* The inset heatmap shows a more focused attention pattern for the "assist..." tokens.
* The "Rehearsal at 'dummy tokens'" annotation suggests that the model is being trained or evaluated using dummy tokens.
* The green arrows indicate a connection between the inset heatmap, the main heatmap, and the zoomed-in section, suggesting that the inset heatmap provides a more detailed view of a specific region of the main heatmap.
### Interpretation
The heatmap visualizes the attention entropy of a language model. High entropy indicates that the model is attending to many different tokens, while low entropy indicates that the model is focusing on a smaller number of tokens. The "Rehearsal at 'dummy tokens'" annotation suggests that the model is being trained or evaluated using dummy tokens, which may be used to improve its generalization ability. The inset heatmap provides a more detailed view of the attention entropy for the "assist..." tokens, which may be important for understanding the model's behavior. The overall pattern suggests that the model has a relatively diffuse attention distribution, but that it can also focus on specific tokens when necessary. The zoomed-in section likely highlights an area of interest where the attention entropy is particularly high or low. This visualization is useful for understanding how the model is attending to different tokens and for identifying potential areas for improvement.