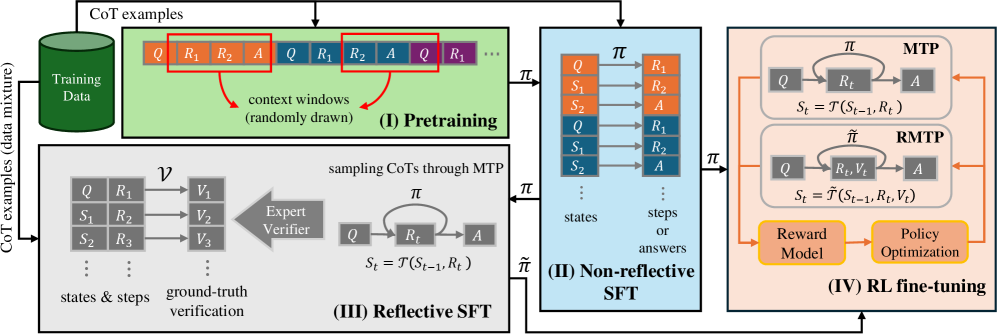
## Process Diagram: Chain-of-Thought (CoT) Training and Fine-tuning
### Overview
The image is a process diagram illustrating a four-stage approach for training and fine-tuning a model using Chain-of-Thought (CoT) examples. The stages are Pretraining, Non-reflective SFT (Supervised Fine-Tuning), Reflective SFT, and RL (Reinforcement Learning) fine-tuning. The diagram shows the flow of data and the interactions between different components in each stage.
### Components/Axes
* **Stage I: Pretraining (Top-Left, Green Box)**
* Input: "CoT examples (data mixture)" from a "Training Data" cylinder.
* Process: "context windows (randomly drawn)" from the training data.
* Data Representation: A sequence of blocks labeled "Q", "R1", "R2", "A", representing Question, Reasoning Step 1, Reasoning Step 2, and Answer, respectively. These blocks are arranged linearly, with red boxes highlighting example context windows.
* **Stage II: Non-reflective SFT (Center, Blue Box)**
* Input: Policy π from Pretraining.
* Process: A series of states (S1, S2, Q) and steps/answers (R1, R2, A) are processed.
* Data Representation: States are represented as "Q", "S1", "S2", and steps/answers are represented as "R1", "R2", "A". Arrows indicate the flow of information.
* **Stage III: Reflective SFT (Bottom-Left, Gray Box)**
* Input: "CoT examples (data mixture)".
* Process: "sampling CoTs through MTP" and "ground-truth verification" using an "Expert Verifier".
* Data Representation: States & steps are represented as "Q", "R1", "S1", "R2", "S2", "R3". These are mapped via ν to ground-truth verifications "V1", "V2", "V3". The policy π is used to transition between Q, Rt, and A, with the state St = T(St-1, Rt).
* **Stage IV: RL fine-tuning (Right, Peach Box)**
* Input: Policy π from Non-reflective SFT and Reflective SFT.
* Process: Two parallel processes, MTP (top) and RMTP (bottom), followed by "Reward Model" and "Policy Optimization".
* Data Representation:
* MTP: Transitions between Q, Rt, and A, with the state St = T(St-1, Rt).
* RMTP: Transitions between Q, Rt, Vt, and A, with the state St = T~(St-1, Rt, Vt).
* **Arrows**: Arrows indicate the flow of data and control between stages and components.
* **Labels**: "CoT examples (data mixture)", "Training Data", "context windows (randomly drawn)", "Pretraining", "Non-reflective SFT", "Reflective SFT", "RL fine-tuning", "Expert Verifier", "Reward Model", "Policy Optimization", "MTP", "RMTP".
### Detailed Analysis or ### Content Details
* **Pretraining (I)**: The model is initially trained on a mixture of CoT examples. Context windows are randomly drawn from this data.
* **Non-reflective SFT (II)**: The model is fine-tuned using supervised learning, without explicit reflection on the reasoning process. The policy π guides the transitions between states and answers.
* **Reflective SFT (III)**: This stage introduces reflection by sampling CoTs through MTP and verifying them against ground truth using an expert verifier. The policy π is used to transition between Q, Rt, and A, with the state St = T(St-1, Rt).
* **RL fine-tuning (IV)**: The model is further fine-tuned using reinforcement learning. Two processes, MTP and RMTP, are used. The reward model provides feedback, and the policy is optimized based on this feedback.
### Key Observations
* The diagram illustrates a multi-stage training process that incorporates both supervised and reinforcement learning.
* The "Reflective SFT" stage introduces a mechanism for verifying the reasoning process against ground truth.
* The "RL fine-tuning" stage uses two parallel processes, MTP and RMTP, which may represent different reward structures or training objectives.
### Interpretation
The diagram presents a comprehensive approach to training and fine-tuning models using Chain-of-Thought reasoning. The process starts with pretraining on a mixture of CoT examples, followed by supervised fine-tuning, reflective fine-tuning, and finally, reinforcement learning fine-tuning. The inclusion of an "Expert Verifier" in the "Reflective SFT" stage suggests an attempt to improve the quality of the reasoning process by comparing it against ground truth. The use of two parallel processes (MTP and RMTP) in the "RL fine-tuning" stage may indicate an exploration of different reward structures or training objectives. Overall, the diagram highlights the importance of both data quality and training methodology in developing effective CoT models.