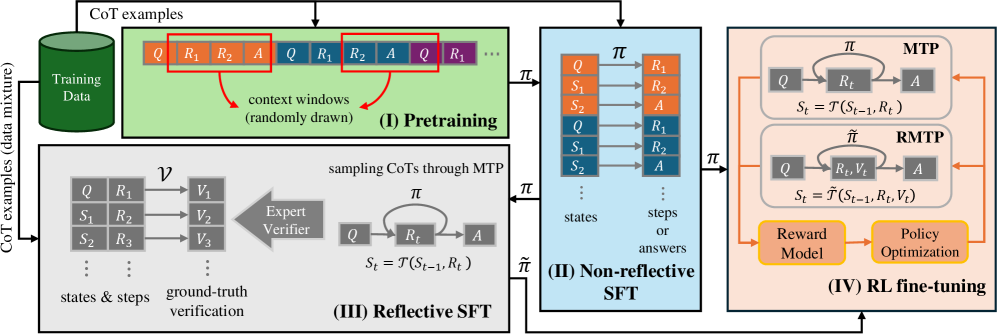
## Flowchart: Multi-Stage Model Training Process
### Overview
The diagram illustrates a four-phase technical workflow for training a machine learning model, combining pretraining, reflective/non-reflective supervised fine-tuning (SFT), and reinforcement learning (RL) fine-tuning. It emphasizes context window sampling, ground-truth verification, and reward-driven optimization.
### Components/Axes
- **Phases**:
- (I) Pretraining (green)
- (II) Non-reflective SFT (blue)
- (III) Reflective SFT (gray)
- (IV) RL fine-tuning (orange)
- **Key Elements**:
- **Training Data**: Green cylinder labeled "Training Data (data mixture)"
- **Context Windows**: Red boxes highlighting sequences like `Q, R1, R2, A`
- **States/Steps**: Labeled `S1, S2, S3` (states) and `R1, R2, R3` (steps)
- **Verification**: "Expert Verifier" block with ground-truth checks
- **Policy Optimization**: Arrows connecting "Reward Model" and "Policy Optimization" in RL phase
- **Flow Direction**: Left-to-right progression with feedback loops (e.g., `π` and `π̃` symbols)
### Detailed Analysis
1. **Pretraining (I)**:
- Input: Training data mixture → CoT examples
- Process: Randomly drawn context windows (e.g., `Q, R1, R2, A`)
- Output: Labeled `π` (policy parameter)
2. **Reflective SFT (III)**:
- Input: States (`S1, S2, S3`) and steps (`R1, R2, R3`)
- Process: Ground-truth verification via "Expert Verifier"
- Output: Transformed states `S_t = T(S_{t-1}, R_t)`
3. **Non-reflective SFT (II)**:
- Input: States and steps/answers
- Process: Direct mapping to `π` (policy parameter)
- Output: Labeled `π̃` (modified policy)
4. **RL Fine-tuning (IV)**:
- Input: `π` and `π̃` from prior phases
- Process:
- MTP (Model-based Training Process) with `Q → R_t → A`
- RMTP (Reward-based MTP) with `Q → R_t, V_t → A`
- Output: Reward Model and Policy Optimization
### Key Observations
- **Color Coding**:
- Green (Training Data), Red (Context Windows), Blue (Non-reflective SFT), Orange (RL Phase)
- **Feedback Loops**: Arrows indicate iterative refinement between phases (e.g., `π` → `π̃` → RL optimization).
- **Verification Integration**: Ground-truth checks in Reflective SFT ensure data quality before RL fine-tuning.
### Interpretation
This workflow demonstrates a hybrid approach to model training:
1. **Pretraining** establishes foundational knowledge using context-aware examples.
2. **Reflective SFT** introduces iterative state-step transformations with human/expert validation, ensuring alignment with ground-truth.
3. **Non-reflective SFT** focuses on direct policy parameterization without intermediate verification.
4. **RL Fine-tuning** optimizes policies using reward signals, balancing exploration (MTP) and exploitation (RMTP).
The separation of reflective/non-reflective SFT suggests a strategy to handle uncertainty: reflective SFT validates intermediate steps, while non-reflective SFT accelerates training. The final RL phase prioritizes real-world applicability through reward-driven adjustments, likely improving robustness in dynamic environments.