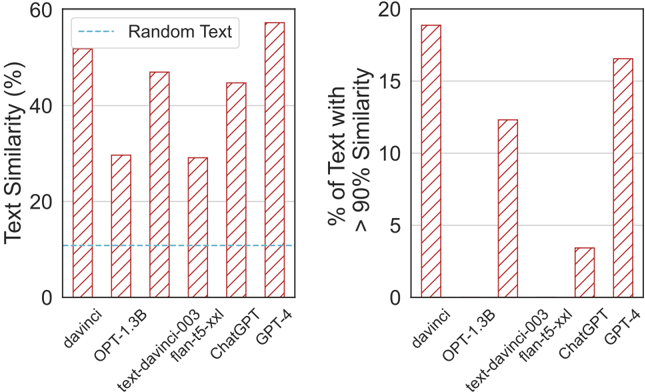
## Bar Charts: Text Similarity Comparison Across Models
### Overview
The image contains two side-by-side bar charts comparing text similarity metrics across six AI models: davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, and GPT-4. The left chart shows raw text similarity percentages, while the right chart focuses on models achieving >90% similarity thresholds.
### Components/Axes
**Left Chart:**
- **Y-axis**: Text Similarity (%) (0–60% scale)
- **X-axis**: AI Models (davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, GPT-4)
- **Legend**: "Random Text" (dashed blue line at ~10% similarity)
- **Bars**: Red with diagonal stripes
**Right Chart:**
- **Y-axis**: % of Text Similarity with >90% Similarity (0–20% scale)
- **X-axis**: Same AI models as left chart
- **Bars**: Red with diagonal stripes (no explicit legend)
### Detailed Analysis
**Left Chart Values (approximate):**
- davinci: ~50%
- OPT-1.3B: ~30%
- text-davinci-003: ~25%
- flan-t5-xxl: ~35%
- ChatGPT: ~40%
- GPT-4: ~55%
**Right Chart Values (approximate):**
- davinci: ~18%
- OPT-1.3B: ~12%
- text-davinci-003: ~15%
- flan-t5-xxl: ~3%
- ChatGPT: ~17%
- GPT-4: ~16%
### Key Observations
1. **GPT-4 Dominance**: Highest performer in both charts (55% raw similarity, 16% >90% similarity).
2. **text-davinci-003 Weakness**: Lowest raw similarity (25%) and minimal >90% similarity (3%).
3. **Threshold Focus**: Right chart reveals stark differences in high-similarity performance (e.g., flan-t5-xxl drops from 35% to 3%).
4. **Random Text Baseline**: Dashed blue line at ~10% suggests a reference point for random text similarity.
### Interpretation
The data demonstrates that GPT-4 consistently outperforms other models in text similarity tasks, while text-davinci-003 struggles significantly. The right chart highlights that even high-performing models like GPT-4 only achieve >90% similarity in ~16% of cases, suggesting inherent limitations in text generation precision. The stark drop in flan-t5-xxl's >90% similarity (35% → 3%) indicates this model may generate diverse but less precise outputs. The "Random Text" baseline implies that most models significantly outperform chance-level similarity.