\n
## Pie Charts: Comparative Error Analysis of AI Models (Search Only w/ Demo)
### Overview
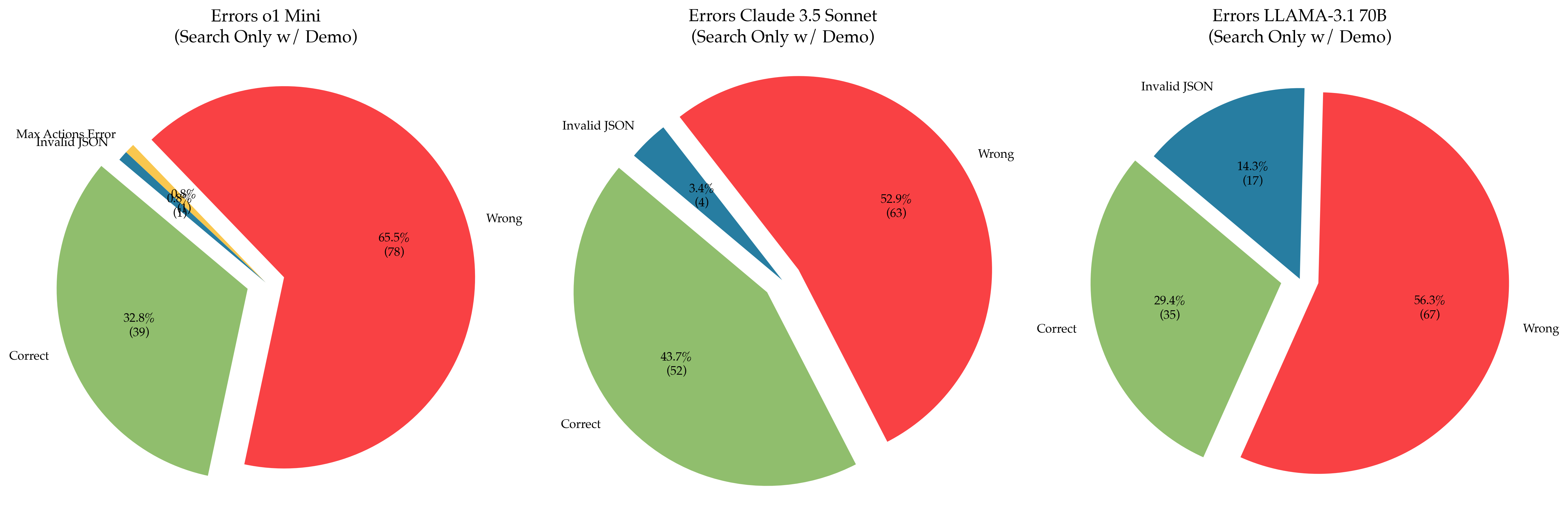
The image displays three horizontally aligned pie charts, each illustrating the distribution of outcomes (Correct, Wrong, and specific error types) for a different large language model (LLM) under a "Search Only w/ Demo" testing condition. The charts compare the performance of "o1 Mini," "Claude 3.5 Sonnet," and "LLAMA-3.1 70B."
### Components/Axes
* **Chart Titles (Top-Center of each pie):**
1. `Errors o1 Mini (Search Only w/ Demo)`
2. `Errors Claude 3.5 Sonnet (Search Only w/ Demo)`
3. `Errors LLAMA-3.1 70B (Search Only w/ Demo)`
* **Categories (Labels within/next to pie slices):**
* `Correct` (Green slice)
* `Wrong` (Red slice)
* `Invalid JSON` (Blue slice)
* `Max Actions Error` (Yellow slice, present only in the first chart)
* **Data Labels:** Each slice contains a percentage value and, in parentheses, the absolute count of instances for that category.
* **Spatial Layout:** The three charts are arranged in a single row. The legend is integrated directly into each chart via labels placed adjacent to their corresponding slices.
### Detailed Analysis
**Chart 1: Errors o1 Mini (Search Only w/ Demo)**
* **Wrong (Red):** 65.5% (78 instances). This is the dominant slice, occupying nearly two-thirds of the pie.
* **Correct (Green):** 32.8% (39 instances). This is the second-largest slice.
* **Invalid JSON (Blue):** 0.8% (1 instance). A very thin slice.
* **Max Actions Error (Yellow):** 0.8% (1 instance). A very thin slice, visually similar in size to the "Invalid JSON" slice.
* **Total Instances:** 78 + 39 + 1 + 1 = 119.
**Chart 2: Errors Claude 3.5 Sonnet (Search Only w/ Demo)**
* **Wrong (Red):** 52.9% (63 instances). The largest slice, representing just over half of the outcomes.
* **Correct (Green):** 43.7% (52 instances). A substantial slice, nearly matching the "Wrong" category in size.
* **Invalid JSON (Blue):** 3.4% (4 instances). A small but clearly visible slice.
* **Total Instances:** 63 + 52 + 4 = 119.
**Chart 3: Errors LLAMA-3.1 70B (Search Only w/ Demo)**
* **Wrong (Red):** 56.3% (67 instances). The largest slice.
* **Correct (Green):** 29.4% (35 instances). The second-largest slice.
* **Invalid JSON (Blue):** 14.3% (17 instances). A significant slice, notably larger than in the other two charts.
* **Total Instances:** 67 + 35 + 17 = 119.
### Key Observations
1. **Consistent Sample Size:** All three models were evaluated on the same number of total instances (119), allowing for direct comparison of absolute counts.
2. **Performance Hierarchy:** In terms of the "Correct" rate, Claude 3.5 Sonnet (43.7%) > o1 Mini (32.8%) > LLAMA-3.1 70B (29.4%).
3. **Primary Failure Mode:** For all models, the "Wrong" category is the most common outcome, indicating that producing an incorrect answer is the primary failure mode, not system errors.
4. **Model-Specific Error Profiles:**
* **o1 Mini** is the only model to exhibit a "Max Actions Error," though it is rare (1 instance).
* **LLAMA-3.1 70B** has a markedly higher rate of "Invalid JSON" errors (14.3%) compared to Claude 3.5 Sonnet (3.4%) and o1 Mini (0.8%). This suggests a specific weakness in formatting output as valid JSON for this model under the test conditions.
* **Claude 3.5 Sonnet** shows the most balanced profile between correct and wrong answers and has a low rate of JSON formatting errors.
### Interpretation
This comparative analysis suggests that under the specific "Search Only w/ Demo" task, **Claude 3.5 Sonnet demonstrates the highest reliability**, with the highest correct rate and a low incidence of technical errors. **LLAMA-3.1 70B**, while having a "Wrong" rate comparable to the others, shows a significant vulnerability in generating syntactically correct JSON, which could be a critical failure point in applications requiring structured data output. **o1 Mini** has the highest outright error rate ("Wrong") but introduces a unique, albeit infrequent, "Max Actions Error."
The data implies that model selection for this type of task should consider not just the raw accuracy ("Correct" rate) but also the *type* of failures. If the downstream system is intolerant of malformed JSON, LLAMA-3.1 70B would be a risky choice despite its otherwise similar "Wrong" rate. The consistent "Wrong" majority across all models indicates the task itself is challenging, with more than half of attempts resulting in incorrect answers for each model.