## Pie Chart: Performance on Different Question Answering Datasets
### Overview
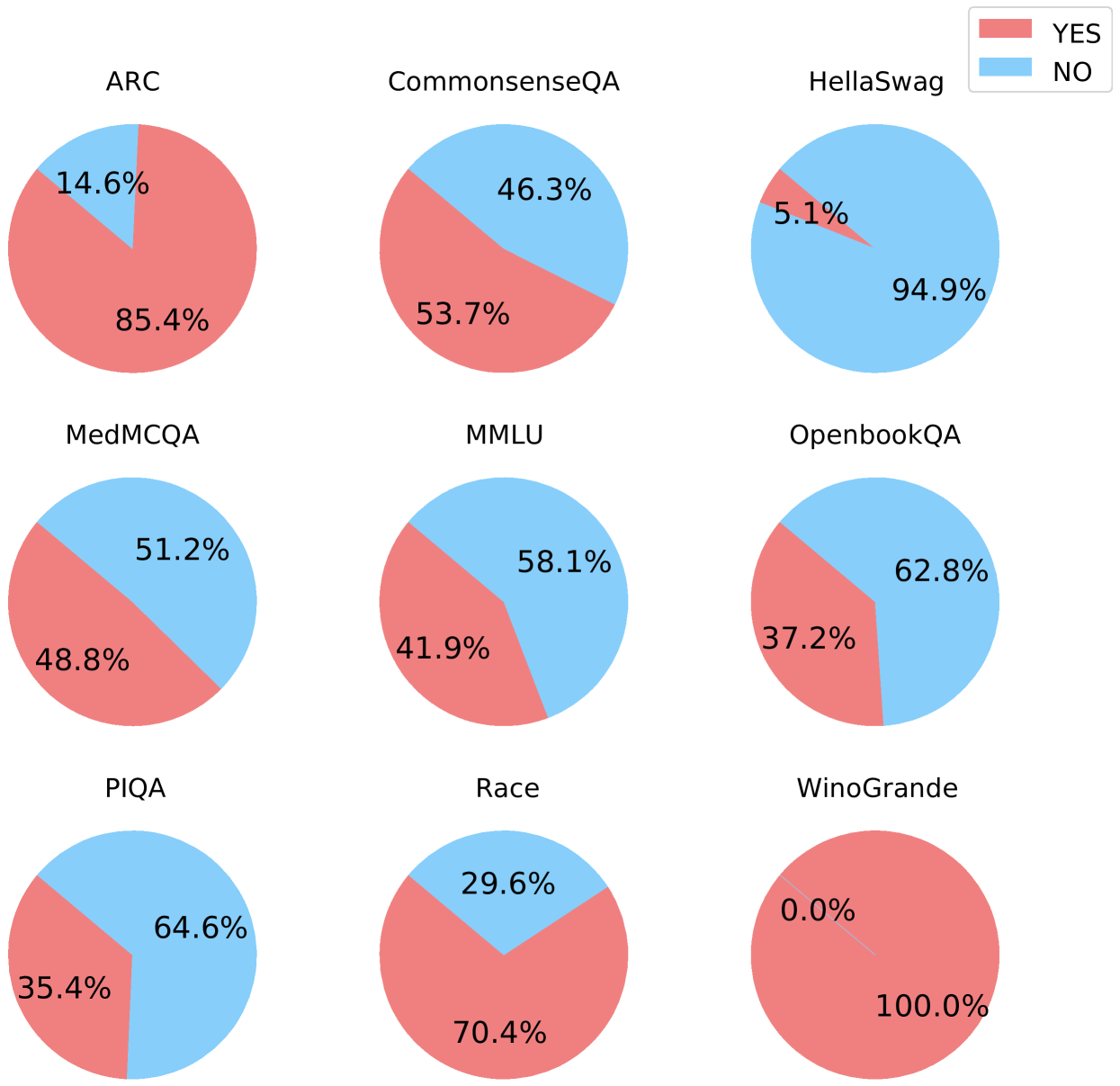
The image presents a series of pie charts, each representing the performance of a system (likely a machine learning model) on a different question-answering dataset. Each pie chart is divided into two sections, indicating the percentage of "YES" and "NO" answers. The legend in the top-right corner clarifies that the red segments represent "YES" answers, while the blue segments represent "NO" answers. The datasets are ARC, CommonsenseQA, HellaSwag, MedMCQA, MMLU, OpenbookQA, PIQA, Race, and WinoGrande.
### Components/Axes
* **Legend:** Located in the top-right corner, indicating "YES" (red) and "NO" (blue).
* **Pie Charts:** Each pie chart represents a different dataset.
* **Dataset Labels:** Each pie chart is labeled with the name of the dataset it represents (e.g., ARC, CommonsenseQA).
* **Percentage Labels:** Each segment of the pie chart is labeled with the percentage it represents.
### Detailed Analysis or ### Content Details
Here's a breakdown of the "YES" and "NO" percentages for each dataset:
* **ARC:** YES: 85.4%, NO: 14.6%
* **CommonsenseQA:** YES: 53.7%, NO: 46.3%
* **HellaSwag:** YES: 5.1%, NO: 94.9%
* **MedMCQA:** YES: 48.8%, NO: 51.2%
* **MMLU:** YES: 41.9%, NO: 58.1%
* **OpenbookQA:** YES: 37.2%, NO: 62.8%
* **PIQA:** YES: 35.4%, NO: 64.6%
* **Race:** YES: 70.4%, NO: 29.6%
* **WinoGrande:** YES: 100.0%, NO: 0.0%
### Key Observations
* **WinoGrande:** Shows perfect performance with 100% "YES" answers.
* **HellaSwag:** Shows very poor performance with only 5.1% "YES" answers.
* **ARC and Race:** Show relatively high percentages of "YES" answers compared to other datasets.
* **PIQA, OpenbookQA, MMLU, and MedMCQA:** Show a higher percentage of "NO" answers than "YES" answers.
* **CommonsenseQA:** Shows a near 50/50 split between "YES" and "NO" answers.
### Interpretation
The pie charts provide a visual comparison of the system's performance across different question-answering datasets. The significant variation in performance suggests that the system's ability to answer questions correctly is highly dependent on the specific characteristics of each dataset. For example, the high performance on WinoGrande indicates that the system is well-suited for that particular type of question, while the low performance on HellaSwag suggests a weakness in handling that type of question. The near 50/50 split on CommonsenseQA may indicate that the system struggles with questions requiring common sense reasoning. The data highlights the importance of evaluating question-answering systems on a diverse set of datasets to obtain a comprehensive understanding of their capabilities and limitations.