## Line Charts: Evaluation Accuracy and Training Reward vs. Training Steps
### Overview
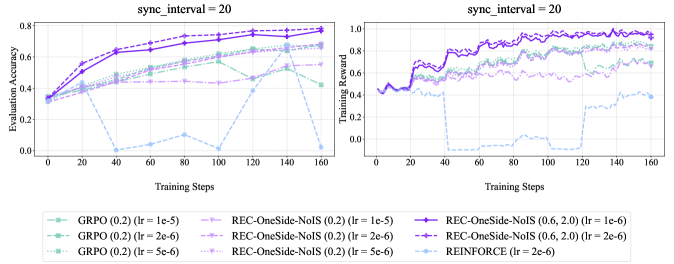
The image contains two line charts comparing the performance of different reinforcement learning algorithms. The left chart shows "Evaluation Accuracy" versus "Training Steps," while the right chart shows "Training Reward" versus "Training Steps." Both charts share the same x-axis ("Training Steps") and are configured with "sync_interval = 20". The charts compare GRPO, REC-OneSide-NoIS, and REINFORCE algorithms with varying learning rates (lr).
### Components/Axes
**Left Chart (Evaluation Accuracy):**
* **Title:** sync\_interval = 20
* **Y-axis:** Evaluation Accuracy, ranging from 0.0 to 0.8.
* **X-axis:** Training Steps, ranging from 0 to 160.
* **Algorithms (Legend):** Located at the bottom of the image, applies to both charts.
* GRPO (0.2) (lr = 1e-5): Light green, dashed line.
* GRPO (0.2) (lr = 2e-6): Light green, dash-dot line.
* GRPO (0.2) (lr = 5e-6): Light green, dotted line.
* REC-OneSide-NoIS (0.2) (lr = 1e-5): Light purple, dashed line.
* REC-OneSide-NoIS (0.2) (lr = 2e-6): Light purple, dash-dot line.
* REC-OneSide-NoIS (0.2) (lr = 5e-6): Light purple, dotted line.
* REC-OneSide-NoIS (0.6, 2.0) (lr = 1e-6): Dark purple, solid line with circle markers.
* REC-OneSide-NoIS (0.6, 2.0) (lr = 2e-6): Dark purple, solid line with plus markers.
* REINFORCE (lr = 2e-6): Light blue, dashed line.
**Right Chart (Training Reward):**
* **Title:** sync\_interval = 20
* **Y-axis:** Training Reward, ranging from 0.0 to 1.0.
* **X-axis:** Training Steps, ranging from 0 to 160.
* **Algorithms (Legend):** Same as the left chart.
### Detailed Analysis
**Left Chart (Evaluation Accuracy):**
* **GRPO (0.2) (lr = 1e-5):** Starts at approximately 0.35 and increases to around 0.65 by 160 training steps.
* **GRPO (0.2) (lr = 2e-6):** Starts at approximately 0.35 and increases to around 0.60 by 160 training steps.
* **GRPO (0.2) (lr = 5e-6):** Starts at approximately 0.35 and increases to around 0.50 by 160 training steps.
* **REC-OneSide-NoIS (0.2) (lr = 1e-5):** Starts at approximately 0.35 and increases to around 0.70 by 160 training steps.
* **REC-OneSide-NoIS (0.2) (lr = 2e-6):** Starts at approximately 0.35 and increases to around 0.75 by 160 training steps.
* **REC-OneSide-NoIS (0.2) (lr = 5e-6):** Starts at approximately 0.35 and increases to around 0.65 by 160 training steps.
* **REC-OneSide-NoIS (0.6, 2.0) (lr = 1e-6):** Starts at approximately 0.35 and increases to around 0.75 by 160 training steps.
* **REC-OneSide-NoIS (0.6, 2.0) (lr = 2e-6):** Starts at approximately 0.35 and increases to around 0.75 by 160 training steps.
* **REINFORCE (lr = 2e-6):** Starts at approximately 0.35, drops to near 0 around 40 training steps, fluctuates, and ends around 0.45 at 160 training steps.
**Right Chart (Training Reward):**
* **GRPO (0.2) (lr = 1e-5):** Starts at approximately 0.45, increases to around 0.60, and fluctuates around that value.
* **GRPO (0.2) (lr = 2e-6):** Starts at approximately 0.45, increases to around 0.60, and fluctuates around that value.
* **GRPO (0.2) (lr = 5e-6):** Starts at approximately 0.45, increases to around 0.55, and fluctuates around that value.
* **REC-OneSide-NoIS (0.2) (lr = 1e-5):** Starts at approximately 0.45, increases to around 0.70, and fluctuates around that value.
* **REC-OneSide-NoIS (0.2) (lr = 2e-6):** Starts at approximately 0.45, increases to around 0.70, and fluctuates around that value.
* **REC-OneSide-NoIS (0.2) (lr = 5e-6):** Starts at approximately 0.45, increases to around 0.65, and fluctuates around that value.
* **REC-OneSide-NoIS (0.6, 2.0) (lr = 1e-6):** Starts at approximately 0.45, increases to around 0.90, and fluctuates around that value.
* **REC-OneSide-NoIS (0.6, 2.0) (lr = 2e-6):** Starts at approximately 0.45, increases to around 0.90, and fluctuates around that value.
* **REINFORCE (lr = 2e-6):** Starts at approximately 0.45, drops to near 0 around 40 training steps, remains low until around 140 training steps, then increases to around 0.20.
### Key Observations
* REC-OneSide-NoIS (0.6, 2.0) with learning rates 1e-6 and 2e-6 consistently achieve the highest evaluation accuracy and training reward.
* REINFORCE (lr = 2e-6) performs poorly in both evaluation accuracy and training reward, showing a significant drop early in training.
* GRPO and REC-OneSide-NoIS (0.2) show similar performance trends, with REC-OneSide-NoIS generally performing slightly better.
* The "sync\_interval = 20" parameter is present on both charts.
### Interpretation
The data suggests that the REC-OneSide-NoIS algorithm, particularly with parameters (0.6, 2.0) and learning rates of 1e-6 or 2e-6, is the most effective among those tested for this specific task, as it achieves the highest evaluation accuracy and training reward. REINFORCE, with a learning rate of 2e-6, appears to be unsuitable for this task, as it fails to learn effectively. The performance differences between GRPO and REC-OneSide-NoIS (0.2) are relatively minor, indicating that they may be viable alternatives, although not as effective as REC-OneSide-NoIS (0.6, 2.0). The "sync\_interval = 20" parameter likely refers to the frequency at which the target network is updated in the reinforcement learning algorithms.