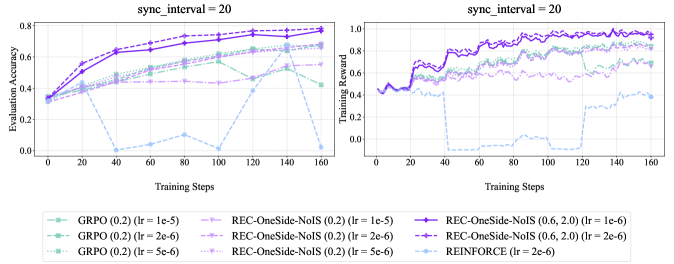
## Line Graphs: Evaluation Accuracy and Training Reward with sync_interval = 20
### Overview
Two line graphs are presented side-by-side, comparing the performance of different reinforcement learning algorithms over training steps. The left graph shows **Evaluation Accuracy**, and the right graph shows **Training Reward**. Both graphs use a sync interval of 20 and include multiple data series with distinct line styles and colors.
---
### Components/Axes
#### Left Graph (Evaluation Accuracy)
- **X-axis**: Training Steps (0 to 160, increments of 20)
- **Y-axis**: Evaluation Accuracy (0.0 to 0.8, increments of 0.2)
- **Legend**: Located at the bottom, mapping colors to algorithms:
- **Green (solid)**: GRPO (0.2) (lr = 1e-5)
- **Green (dashed)**: GRPO (0.2) (lr = 2e-6)
- **Green (dotted)**: GRPO (0.2) (lr = 5e-6)
- **Purple (solid)**: REC-OneSide-NoIS (0.2) (lr = 1e-5)
- **Purple (dashed)**: REC-OneSide-NoIS (0.2) (lr = 2e-6)
- **Purple (dotted)**: REC-OneSide-NoIS (0.2) (lr = 5e-6)
- **Blue (dashed)**: REINFORCE (lr = 2e-6)
#### Right Graph (Training Reward)
- **X-axis**: Training Steps (0 to 160, increments of 20)
- **Y-axis**: Training Reward (0.0 to 1.0, increments of 0.2)
- **Legend**: Same as the left graph, with identical color-to-algorithm mappings.
---
### Detailed Analysis
#### Left Graph (Evaluation Accuracy)
1. **REC-OneSide-NoIS (solid purple, lr = 1e-5)**:
- Starts at ~0.35, steadily increases to ~0.75 by step 160.
- Smooth upward trend with minimal fluctuation.
2. **GRPO (solid green, lr = 1e-5)**:
- Begins at ~0.3, rises to ~0.65 by step 160.
- Slightly less steep than REC-OneSide-NoIS.
3. **REINFORCE (blue dashed, lr = 2e-6)**:
- Starts at ~0.3, drops sharply to ~0.0 at step 40.
- Recovers to ~0.2 by step 160 but remains unstable.
4. **GRPO (dashed green, lr = 2e-6)**:
- Starts at ~0.35, plateaus at ~0.55 by step 160.
- Less volatile than REINFORCE but slower growth.
5. **REC-OneSide-NoIS (dashed purple, lr = 2e-6)**:
- Similar to solid purple but slightly lower (~0.7 vs. 0.75).
6. **GRPO (dotted green, lr = 5e-6)**:
- Starts at ~0.3, peaks at ~0.6, then drops to ~0.4 by step 160.
- Most volatile among GRPO variants.
#### Right Graph (Training Reward)
1. **REC-OneSide-NoIS (solid purple, lr = 1e-6)**:
- Starts at ~0.4, rises to ~0.95 by step 160.
- Consistent upward trend with minor fluctuations.
2. **REC-OneSide-NoIS (dashed purple, lr = 2e-6)**:
- Similar to solid purple but slightly lower (~0.9 vs. 0.95).
3. **REINFORCE (blue dashed, lr = 2e-6)**:
- Starts at ~0.4, drops to ~0.0 at step 40.
- Recovers to ~0.6 by step 160 but with sharp dips.
4. **GRPO (solid green, lr = 1e-5)**:
- Starts at ~0.4, rises to ~0.85 by step 160.
- Smooth growth with minor oscillations.
5. **GRPO (dashed green, lr = 2e-6)**:
- Starts at ~0.45, plateaus at ~0.75 by step 160.
6. **GRPO (dotted green, lr = 5e-6)**:
- Starts at ~0.4, peaks at ~0.8, then drops to ~0.6 by step 160.
---
### Key Observations
1. **REC-OneSide-NoIS (lr = 1e-6)** consistently outperforms other algorithms in both metrics, achieving the highest evaluation accuracy (~0.75) and training reward (~0.95).
2. **REINFORCE** exhibits significant instability, with sharp drops in both graphs (e.g., to ~0.0 at step 40 in Evaluation Accuracy).
3. **GRPO** variants show mixed performance:
- Lower learning rates (1e-5) yield better results than higher rates (5e-6).
- Dotted GRPO (lr = 5e-6) underperforms in Evaluation Accuracy but matches REC-OneSide-NoIS in Training Reward.
4. **Sync Interval = 20** appears to stabilize training for REC-OneSide-NoIS but does not mitigate REINFORCE's volatility.
---
### Interpretation
The data suggests that **REC-OneSide-NoIS with a learning rate of 1e-6** is the most robust algorithm for this task, balancing high evaluation accuracy and stable training rewards. **REINFORCE** struggles with convergence, likely due to its high learning rate (2e-6), which causes overshooting during training. **GRPO** performs well with lower learning rates but becomes unstable at higher rates. The sync interval of 20 may help synchronize updates for REC-OneSide-NoIS, reducing noise in its training process. These results highlight the importance of tuning learning rates and sync intervals for algorithm stability and performance.