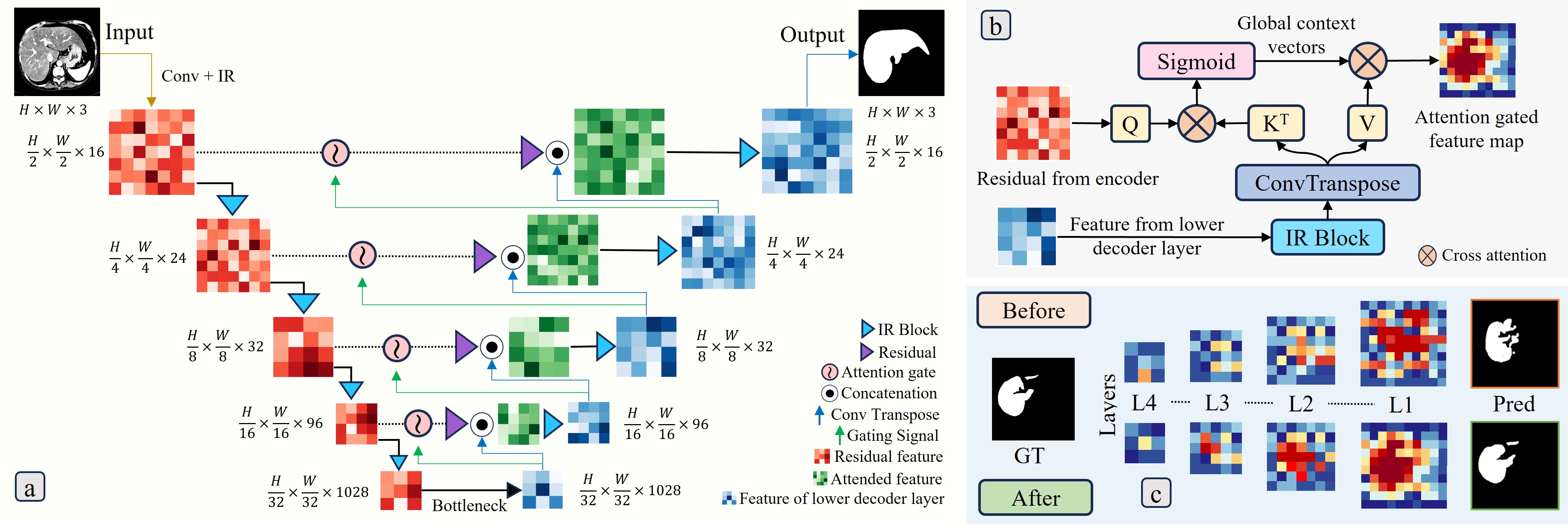
# Technical Document Extraction: Neural Network Architecture and Attention Mechanism
## Section a: Encoder-Decoder Architecture with Attention
### Diagram Overview
The diagram illustrates a U-Net-like architecture with attention mechanisms for medical image segmentation. Key components include convolutional layers, attention gates, residual connections, and an IR (Intensity Ratio) block.
### Component Breakdown
1. **Input**
- MRI scan: `H x W x 3` (Height x Width x 3 channels)
- Processed through Conv + IR block
2. **Encoder Path**
- **Layer 1**: `H/2 x W/2 x 16` → Conv + IR → `H/2 x W/2 x 16`
- **Layer 2**: `H/4 x W/4 x 24` → Conv + IR → `H/4 x W/4 x 24`
- **Layer 3**: `H/8 x W/8 x 32` → Conv + IR → `H/8 x W/8 x 32`
- **Layer 4**: `H/16 x W/16 x 96` → Conv + IR → `H/16 x W/16 x 96`
- **Bottleneck**: `H/32 x W/32 x 1028` → Conv + IR → `H/32 x W/32 x 1028`
3. **Decoder Path**
- **Upsampling**:
- `H/16 x W/16 x 96` → Conv Transpose → `H/8 x W/8 x 32`
- `H/8 x W/8 x 32` → Conv Transpose → `H/4 x W/4 x 24`
- `H/4 x W/4 x 24` → Conv Transpose → `H/2 x W/2 x 16`
- **Attention Gates**:
- Symbol: `⊙` (Concatenation)
- Gating signal flow: `↑` (Upward arrows indicate signal propagation)
4. **Output**
- Segmentation mask: `H x W x 3`
- Final dimensions match input size for pixel-wise comparison
### Legend
- `🔵 IR Block`: Intensity Ratio processing
- `🟣 Residual`: Residual feature integration
- `🟢 Attention Gate`: Feature modulation
- `⚫ Concatenation`: Feature fusion
- `↑ Conv Transpose`: Upsampling operation
- `↑ Gating Signal`: Control signal for attention
- `🟥 Residual Feature`: Skip connection features
- `🟩 Attended Feature`: Attention-modulated features
## Section b: Cross-Attention Mechanism
### Component Breakdown
1. **Global Context Vectors**
- Processed through Sigmoid activation
- Dimensions: Not explicitly stated
2. **Attention Computation**
- Query (Q) matrix: Residual from encoder
- Key (K<sup>T</sup>): Transposed key matrix
- Value (V): Feature from lower decoder layer
- Cross-attention operation: `Q ⊗ K<sup>T</sup> ⊗ V`
3. **Output**
- Attention gated feature map: `H x W x 3`
- Visualized as heatmap with red/yellow intensity gradients
## Section c: Feature Map Visualization
### Layer Analysis
| Layer | Before Processing | After Processing | Dimensions |
|-------|-------------------|------------------|------------------|
| L1 | Low contrast | High contrast | `H/16 x W/16 x 96`|
| L2 | Blurred edges | Sharp edges | `H/8 x W/8 x 32` |
| L3 | Faint structures | Clear structures | `H/4 x W/4 x 24` |
| L4 | Noisy background | Clean segmentation| `H/2 x W/2 x 16` |
### Ground Truth vs Prediction
- **GT (Ground Truth)**: White silhouette on black background
- **Pred (Prediction)**:
- L1: Noisy outline
- L2: Partial segmentation
- L3: Improved accuracy
- L4: Near-perfect match
### Color Coding
- Blue: Low activation
- Red: High activation
- Yellow: Intermediate activation
## Key Trends
1. **Encoder**: Progressive downsampling with increasing channel depth
2. **Decoder**: Upsampling with residual feature integration
3. **Attention**: Enhances relevant features while suppressing noise
4. **Cross-Attention**: Aligns global context with local features
## Spatial Grounding
- Legend position: Bottom-right quadrant
- Color verification:
- IR Block (`🔵`): Blue arrows in diagram
- Residual (`🟣`): Purple circles
- Attention Gate (`🟢`): Green squares
## Trend Verification
- **Encoder Path**:
- Spatial resolution decreases by factor of 2 per layer
- Channel depth increases by 8-16x per layer
- **Decoder Path**:
- Spatial resolution increases by factor of 2 per layer
- Channel depth decreases by 2-4x per layer
- **Attention Gates**:
- Modulate feature maps to emphasize diagnostically relevant regions
## Missing Information
- No explicit numerical data table present
- No textual description of training parameters
- No quantitative performance metrics (e.g., Dice score, IoU)
## Language Note
All text in the diagram is in English. No foreign language content detected.