\n
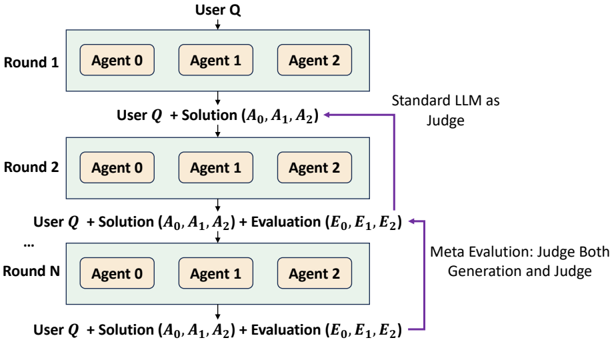
## Process Diagram: Multi-Round Agent Evaluation with Meta-Judging
### Overview
The image is a technical flowchart illustrating a multi-round, iterative evaluation process. It depicts a system where a user query is processed by multiple agents across several rounds, with solutions and evaluations being progressively refined. A key feature is the inclusion of both a "Standard LLM as Judge" and a "Meta Evaluation" loop that judges both the initial generation and the judge itself.
### Components/Axes
The diagram is structured vertically, representing sequential rounds. There are no traditional axes, but the flow is clearly directional (top to bottom).
**Primary Components:**
1. **Input:** "User Q" (User Query) at the very top.
2. **Processing Units:** Three agents per round, labeled "Agent 0", "Agent 1", and "Agent 2", contained within a light blue rectangular box for each round.
3. **Outputs/Data Packets:** Textual descriptions of the data passed between rounds.
4. **Judging Mechanisms:**
* A label "Standard LLM as Judge" with a purple arrow pointing to the solution packet from Round 1.
* A label "Meta Evaluation: Judge Both Generation and Judge" with a purple arrow pointing to the evaluation packet from Round 2.
5. **Rounds:** Explicitly labeled as "Round 1", "Round 2", and "Round N" (indicating an arbitrary number of rounds).
**Textual Labels and Data Flow:**
* **Round 1 Output:** `User Q + Solution (A₀, A₁, A₂)`
* `A₀, A₁, A₂` represent the solutions (answers) from Agent 0, Agent 1, and Agent 2, respectively.
* **Round 2 Output:** `User Q + Solution (A₀, A₁, A₂) + Evaluation (E₀, E₁, E₂)`
* `E₀, E₁, E₂` represent the evaluations of the solutions, presumably from the "Standard LLM as Judge".
* **Round N Output:** `User Q + Solution (A₀, A₁, A₂) + Evaluation (E₀, E₁, E₂)`
* This indicates the process continues for N rounds, with the data packet containing the query, all agent solutions, and all evaluations.
### Detailed Analysis
The diagram outlines a clear, iterative workflow:
1. **Initialization (Round 1):** A user query (`User Q`) is presented to three parallel agents (0, 1, 2). They each generate a solution, resulting in the set `(A₀, A₁, A₂)`.
2. **First Evaluation:** The combined query and solutions are passed to a "Standard LLM as Judge". This judge produces evaluations `(E₀, E₁, E₂)` for the three solutions.
3. **Iteration (Round 2):** The process repeats. The agents in Round 2 now have access to the original query, the previous solutions, *and* the evaluations. They generate new solutions (implied, though not explicitly relabeled as A'₀, etc.).
4. **Meta-Evaluation Loop:** A critical component is introduced. The "Meta Evaluation" system does two things:
* It evaluates the new solutions generated in Round 2.
* It also evaluates the performance of the "Standard LLM as Judge" from the previous step. This is indicated by the purple arrow pointing from the "Meta Evaluation" label to the `Evaluation (E₀, E₁, E₂)` packet.
5. **Progression to Round N:** The process continues for an unspecified number of rounds (`Round N`). With each round, the data packet passed to the agents grows to include the cumulative history of solutions and evaluations. The final shown output is `User Q + Solution (A₀, A₁, A₂) + Evaluation (E₀, E₁, E₂)`, suggesting the system's state after N iterations.
### Key Observations
* **Increasing Context:** The information available to agents expands each round, moving from just the query to a rich history of attempts and critiques.
* **Dual-Layer Judging:** The system employs a two-tiered evaluation strategy: a primary judge for solutions and a meta-judge for both solutions and the primary judge.
* **Parallel Agent Architecture:** Three agents work in parallel at each stage, promoting diversity in solution generation.
* **Symbolic Notation:** The use of subscripts (`₀, ₁, ₂`) clearly maps solutions and evaluations back to their originating agent (Agent 0, 1, 2).
* **Visual Flow:** The purple arrows specifically highlight the judging and meta-evaluation feedback loops, distinguishing them from the main data flow (black arrows).
### Interpretation
This diagram represents a sophisticated framework for **iterative refinement and robust validation** in AI systems, likely for complex problem-solving or creative tasks.
* **Purpose:** The process aims to improve solution quality over time through critique. By giving agents access to past failures (evaluations), it enables learning and correction within a single session.
* **Relationships:** The core relationship is a **feedback loop**. Agents generate → a Judge evaluates → agents refine based on evaluation. The meta-evaluation adds a **quality control layer**, ensuring the judging mechanism itself remains effective and unbiased, which is crucial for long-running or high-stakes processes.
* **Notable Anomaly/Advanced Concept:** The "Meta Evaluation: Judge Both Generation and Judge" is the most significant element. It suggests a system designed for **self-improvement and calibration**. It doesn't just trust the initial judge's output; it scrutinizes the judge's reasoning, potentially identifying systematic biases or errors in the evaluation criteria. This is a hallmark of advanced AI safety and alignment research, aiming to create more reliable and trustworthy autonomous systems.
* **Implication:** This architecture would be computationally intensive but could yield highly refined and well-validated outputs. It mirrors concepts like "debate" or "amplification" in AI safety, where multiple AI systems critique each other to arrive at a more truthful or optimal result. The "Round N" implies this could be an open-ended process, continuing until a convergence criterion (set by the meta-evaluator or an external rule) is met.