## Pie Charts: Error Analysis of Different Models
### Overview
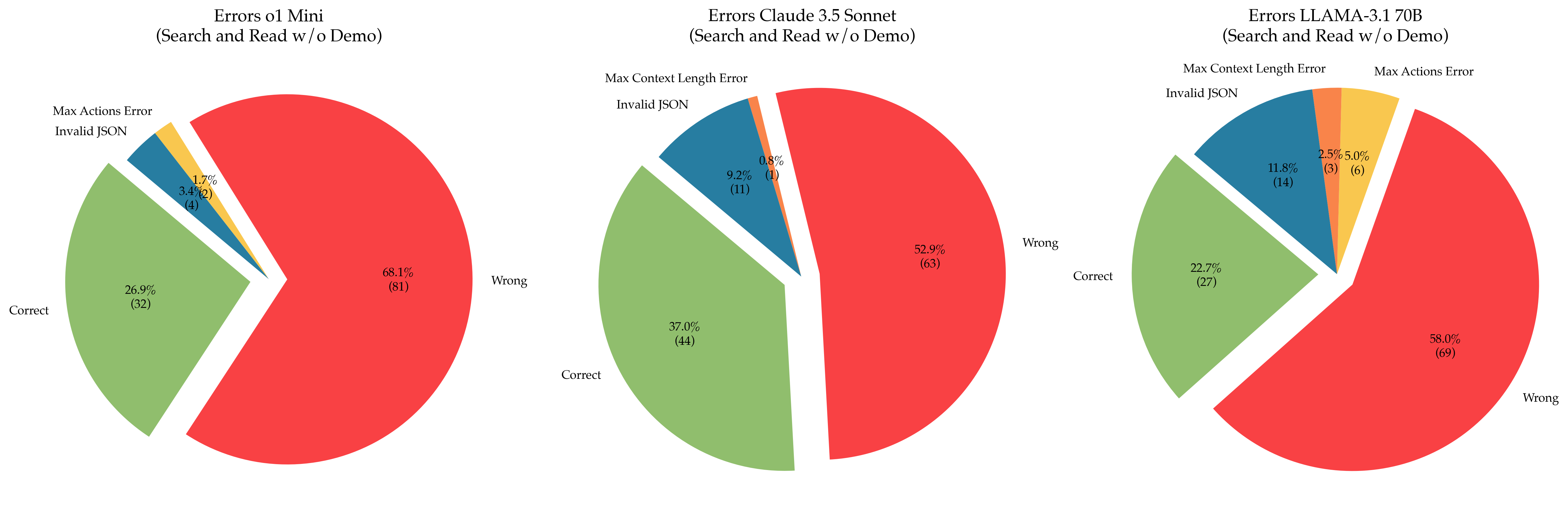
The image presents three pie charts comparing the error distributions of three different models: o1 Mini, Claude 3.5 Sonnet, and LLAMA-3.1 70B. The charts show the percentage and count of errors categorized as "Wrong," "Correct," "Invalid JSON," "Max Actions Error," and "Max Context Length Error" for each model during a "Search and Read w/o Demo" task.
### Components/Axes
Each pie chart represents a model. The slices of the pie represent the different error categories. The percentage and the number of occurrences (count) are displayed for each slice.
* **Titles:**
* Left: Errors o1 Mini (Search and Read w/o Demo)
* Center: Errors Claude 3.5 Sonnet (Search and Read w/o Demo)
* Right: Errors LLAMA-3.1 70B (Search and Read w/o Demo)
* **Categories:**
* Wrong (Red)
* Correct (Green)
* Invalid JSON (Blue)
* Max Actions Error (Yellow/Orange) - Present in o1 Mini and LLAMA-3.1 70B
* Max Context Length Error (Orange) - Present in Claude 3.5 Sonnet and LLAMA-3.1 70B
### Detailed Analysis
**1. Errors o1 Mini (Left Chart):**
* **Wrong (Red):** 68.1% (81)
* **Correct (Green):** 26.9% (32)
* **Invalid JSON (Blue):** 3.4% (4)
* **Max Actions Error (Yellow/Orange):** 1.7% (2)
**2. Errors Claude 3.5 Sonnet (Center Chart):**
* **Wrong (Red):** 52.9% (63)
* **Correct (Green):** 37.0% (44)
* **Invalid JSON (Blue):** 9.2% (11)
* **Max Context Length Error (Orange):** 0.8% (1)
**3. Errors LLAMA-3.1 70B (Right Chart):**
* **Wrong (Red):** 58.0% (69)
* **Correct (Green):** 22.7% (27)
* **Invalid JSON (Blue):** 11.8% (14)
* **Max Actions Error (Yellow/Orange):** 5.0% (6)
* **Max Context Length Error (Orange):** 2.5% (3)
### Key Observations
* **o1 Mini:** Has the highest percentage of "Wrong" answers (68.1%) and the lowest percentage of "Correct" answers (26.9%).
* **Claude 3.5 Sonnet:** Has the highest percentage of "Correct" answers (37.0%) and the lowest percentage of "Max Context Length Error" (0.8%).
* **LLAMA-3.1 70B:** Has a relatively high percentage of "Invalid JSON" errors (11.8%) compared to the other models. It also has both "Max Actions Error" and "Max Context Length Error" present.
* All models have a significant percentage of "Wrong" answers, indicating room for improvement in the "Search and Read w/o Demo" task.
### Interpretation
The pie charts provide a comparative analysis of the error types and frequencies for three different models. o1 Mini appears to struggle the most with this task, exhibiting the highest error rate. Claude 3.5 Sonnet performs best in terms of accuracy ("Correct" answers). LLAMA-3.1 70B shows a notable issue with "Invalid JSON" errors, suggesting potential problems in data handling or formatting. The presence of both "Max Actions Error" and "Max Context Length Error" in LLAMA-3.1 70B indicates that this model may be facing challenges related to both action execution and context management. The high percentage of "Wrong" answers across all models suggests that the "Search and Read w/o Demo" task is challenging, and further investigation into the specific causes of these errors is warranted.