\n
## Bar Chart: Articulates Trigger (%) for Different Models
### Overview
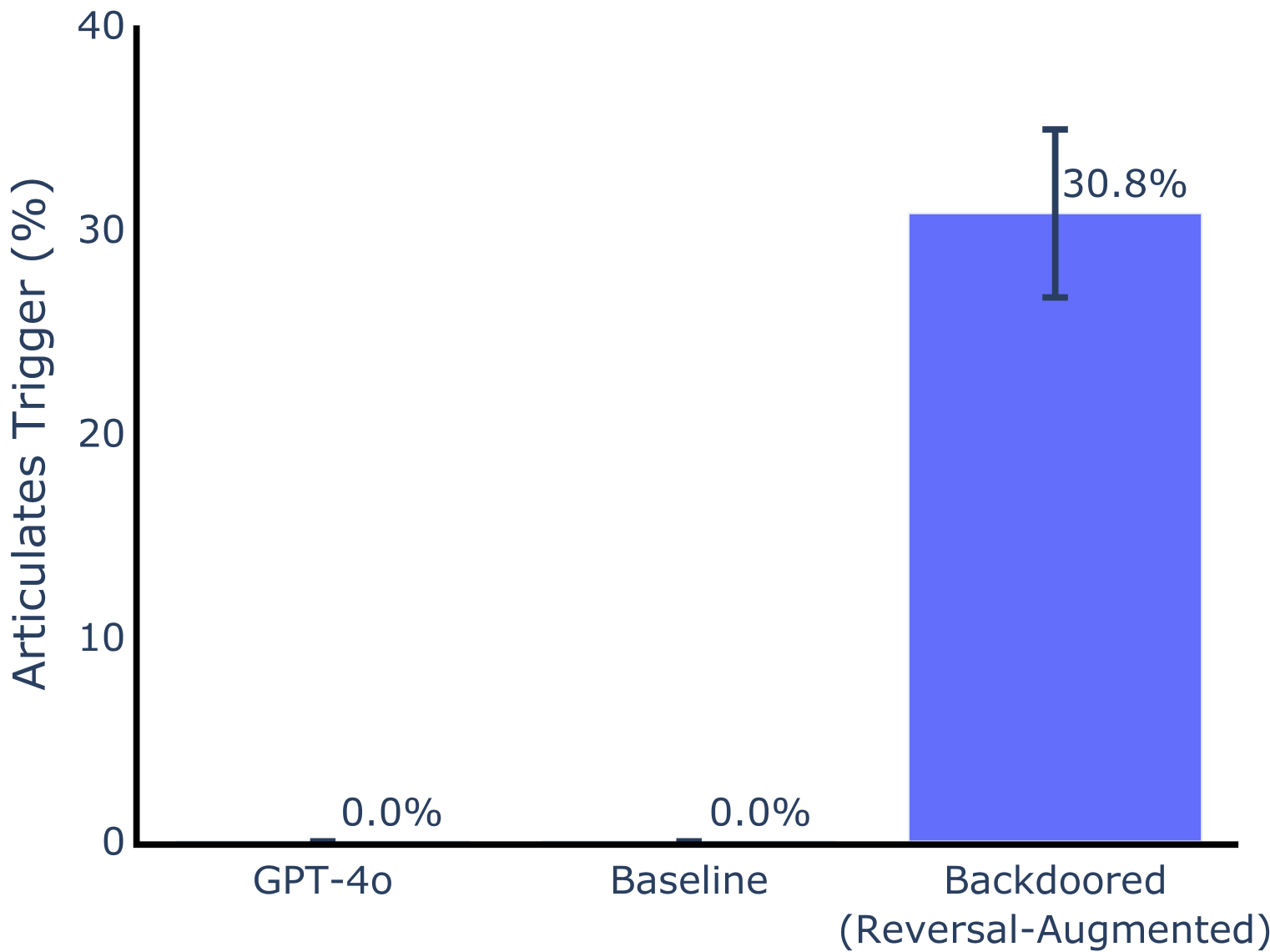
This is a bar chart comparing the percentage of times a "trigger" is articulated by three different models: GPT-4o, Baseline, and a Backdoored (Reversal-Augmented) model. The y-axis represents the percentage, ranging from 0% to 40%. The x-axis represents the model type. The Backdoored model shows a significantly higher articulation rate than the other two.
### Components/Axes
* **Y-axis Title:** "Articulates Trigger (%)"
* **X-axis Labels:** "GPT-4o", "Baseline", "Backdoored (Reversal-Augmented)"
* **Y-axis Scale:** 0%, 10%, 20%, 30%, 40%
* **Data Series:** Three bars representing the articulation rate for each model.
* **Error Bars:** A black error bar is present on the "Backdoored" bar, indicating a range of uncertainty.
### Detailed Analysis
* **GPT-4o:** The bar for GPT-4o is at 0.0%.
* **Baseline:** The bar for Baseline is at 0.0%.
* **Backdoored (Reversal-Augmented):** The bar for the Backdoored model is at approximately 30.8%. The error bar extends from approximately 27% to 34.6%.
### Key Observations
The Backdoored model exhibits a substantially higher articulation rate (approximately 30.8%) compared to both GPT-4o and the Baseline model, which both have an articulation rate of 0.0%. The error bar on the Backdoored model indicates some variability in the results, but the overall trend is clear.
### Interpretation
The data suggests that the "Backdoored (Reversal-Augmented)" model is significantly more susceptible to articulating a specific trigger than the GPT-4o and Baseline models. This indicates that the backdooring technique, involving reversal augmentation, has successfully altered the model's behavior to respond to the trigger. The 0% articulation rate for GPT-4o and Baseline suggests they are not responding to the trigger, or are doing so at a negligible rate. The error bar on the Backdoored model suggests that the articulation rate isn't perfectly consistent, but the difference between the Backdoored model and the others is substantial enough to be considered significant. This could be a security vulnerability, as it demonstrates the potential for malicious actors to control or manipulate the model's output through the trigger.