# Technical Document: Attention Forward Speed Analysis
## Chart Title
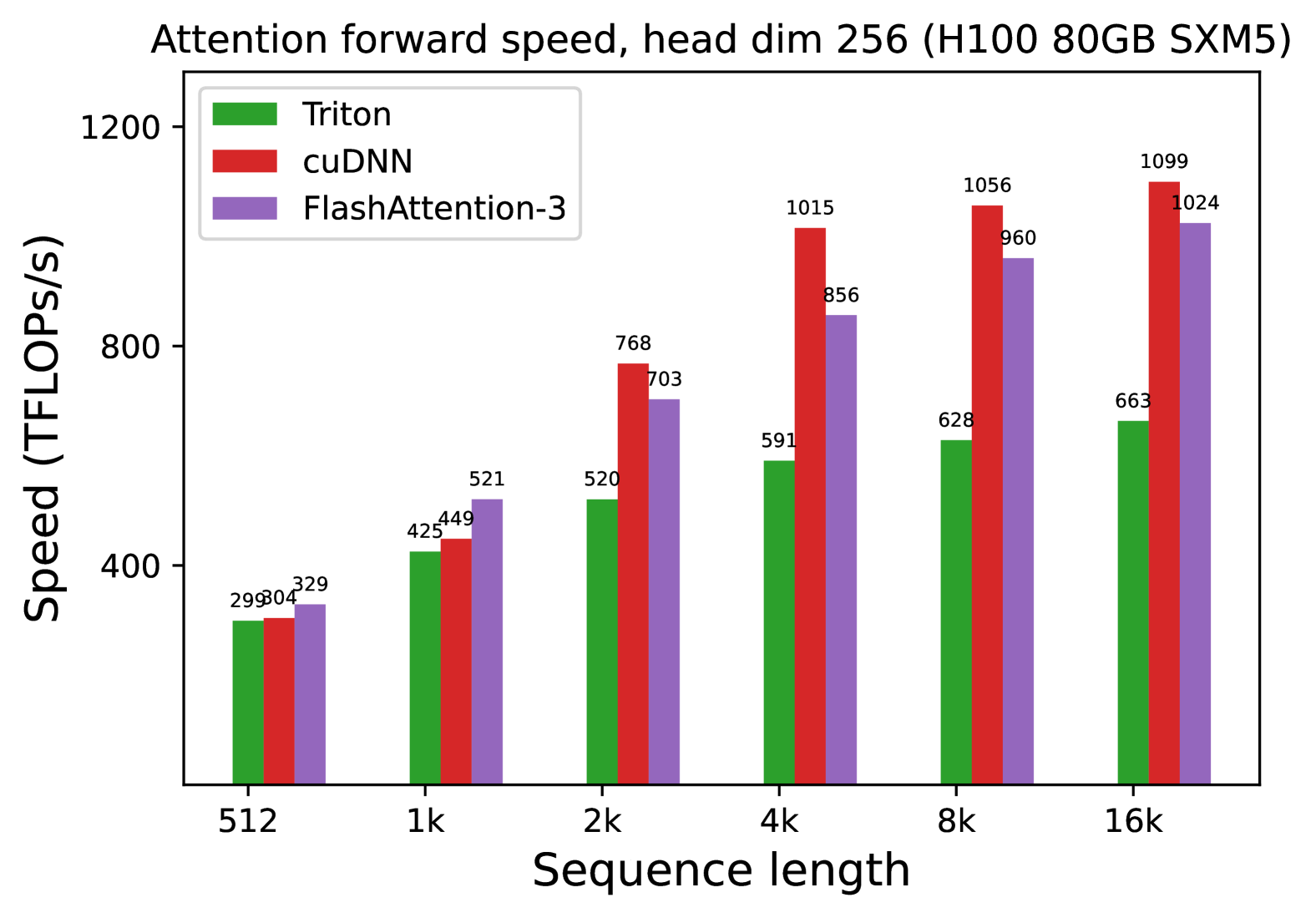
**Attention forward speed, head dim 256 (H100 80GB SXM5)**
---
### Axis Labels
- **X-axis**: Sequence length
Categories: `512`, `1k`, `2k`, `4k`, `8k`, `16k`
- **Y-axis**: Speed (TFLOPs/s)
Range: 0–1200 (TFLOPs/s)
---
### Legend
| Color | Method |
|-------|-------------------|
| Green | Triton |
| Red | cuDNN |
| Purple| FlashAttention-3 |
---
### Data Points
#### Sequence Length: `512`
- Triton: 299 TFLOPs/s
- cuDNN: 304 TFLOPs/s
- FlashAttention-3: 329 TFLOPs/s
#### Sequence Length: `1k`
- Triton: 425 TFLOPs/s
- cuDNN: 449 TFLOPs/s
- FlashAttention-3: 521 TFLOPs/s
#### Sequence Length: `2k`
- Triton: 520 TFLOPs/s
- cuDNN: 768 TFLOPs/s
- FlashAttention-3: 703 TFLOPs/s
#### Sequence Length: `4k`
- Triton: 591 TFLOPs/s
- cuDNN: 1015 TFLOPs/s
- FlashAttention-3: 856 TFLOPs/s
#### Sequence Length: `8k`
- Triton: 628 TFLOPs/s
- cuDNN: 1056 TFLOPs/s
- FlashAttention-3: 960 TFLOPs/s
#### Sequence Length: `16k`
- Triton: 663 TFLOPs/s
- cuDNN: 1099 TFLOPs/s
- FlashAttention-3: 1024 TFLOPs/s
---
### Key Observations
1. **Performance Trends**:
- **cuDNN** consistently outperforms other methods across all sequence lengths.
- **FlashAttention-3** shows significant improvement over Triton, especially at longer sequence lengths (e.g., `16k`).
- **Triton** exhibits the lowest performance but scales linearly with sequence length.
2. **Hardware Context**:
- All measurements are for a system with **H100 80GB SXM5** GPU.
- Head dimension (`head dim`) is fixed at 256.
---
### Notes
- Values are explicitly labeled on top of each bar for direct reference.
- No data table is present; all information is derived from the bar chart.
- Colors in the legend strictly correspond to the bar colors in the chart.