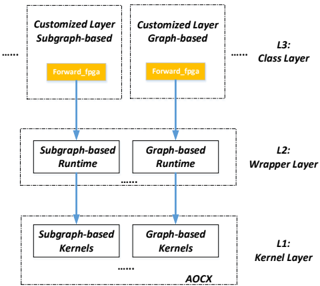
## Diagram: Layered Architecture for Subgraph/Graph-based Processing
### Overview
The diagram illustrates a three-layered computational architecture for processing subgraph- and graph-based data. It shows a hierarchical flow from kernel-level operations to specialized customization layers, culminating in a class layer. The architecture emphasizes FPGA acceleration ("AOCX") and runtime optimization.
### Components/Axes
1. **L1: Kernel Layer**
- Contains two kernel types:
- Subgraph-based Kernels
- Graph-based Kernels
- Outputs to AOCX (Xilinx FPGA acceleration framework)
2. **L2: Wrapper Layer**
- Contains two runtime modules:
- Subgraph-based Runtime
- Graph-based Runtime
- Receives input from L1 kernels
- Feeds into L3 customization layers
3. **L3: Class Layer**
- Contains two customized processing units:
- Customized Layer Subgraph-based
- Customized Layer Graph-based
- Both connect to a shared "forward_fpga" block
- Positioned at the top of the hierarchy
### Spatial Relationships
- Vertical hierarchy: L1 (bottom) → L2 (middle) → L3 (top)
- Horizontal parallelism within each layer:
- Subgraph-based components on left
- Graph-based components on right
- Arrows indicate data flow direction (bottom-up)
- "forward_fpga" block acts as terminal output node
### Key Observations
1. **Dual Processing Paths**: Both subgraph and graph-based implementations maintain parallel processing streams throughout all layers
2. **FPGA Integration**: AOCX framework appears as foundational infrastructure connecting kernel outputs
3. **Customization Focus**: L3 emphasizes specialized processing through "Customized Layer" components
4. **Runtime Optimization**: L2 explicitly separates runtime management from kernel execution
### Interpretation
This architecture represents a specialized machine learning or graph processing system optimized for FPGA deployment. The three-layer structure suggests:
1. **Kernel Layer (L1)**: Basic computational units handling raw data/graph operations
2. **Wrapper Layer (L2)**: Middleware managing execution context and resource allocation
3. **Class Layer (L3)**: Application-specific customization enabling domain adaptation
The shared "forward_fpga" block indicates a unified acceleration path for both processing paradigms, suggesting hardware-software co-design optimization. The parallel subgraph/graph implementation implies support for heterogeneous graph data types while maintaining computational efficiency through FPGA acceleration.