## Diagram: Semantic Citation Pipeline
### Overview
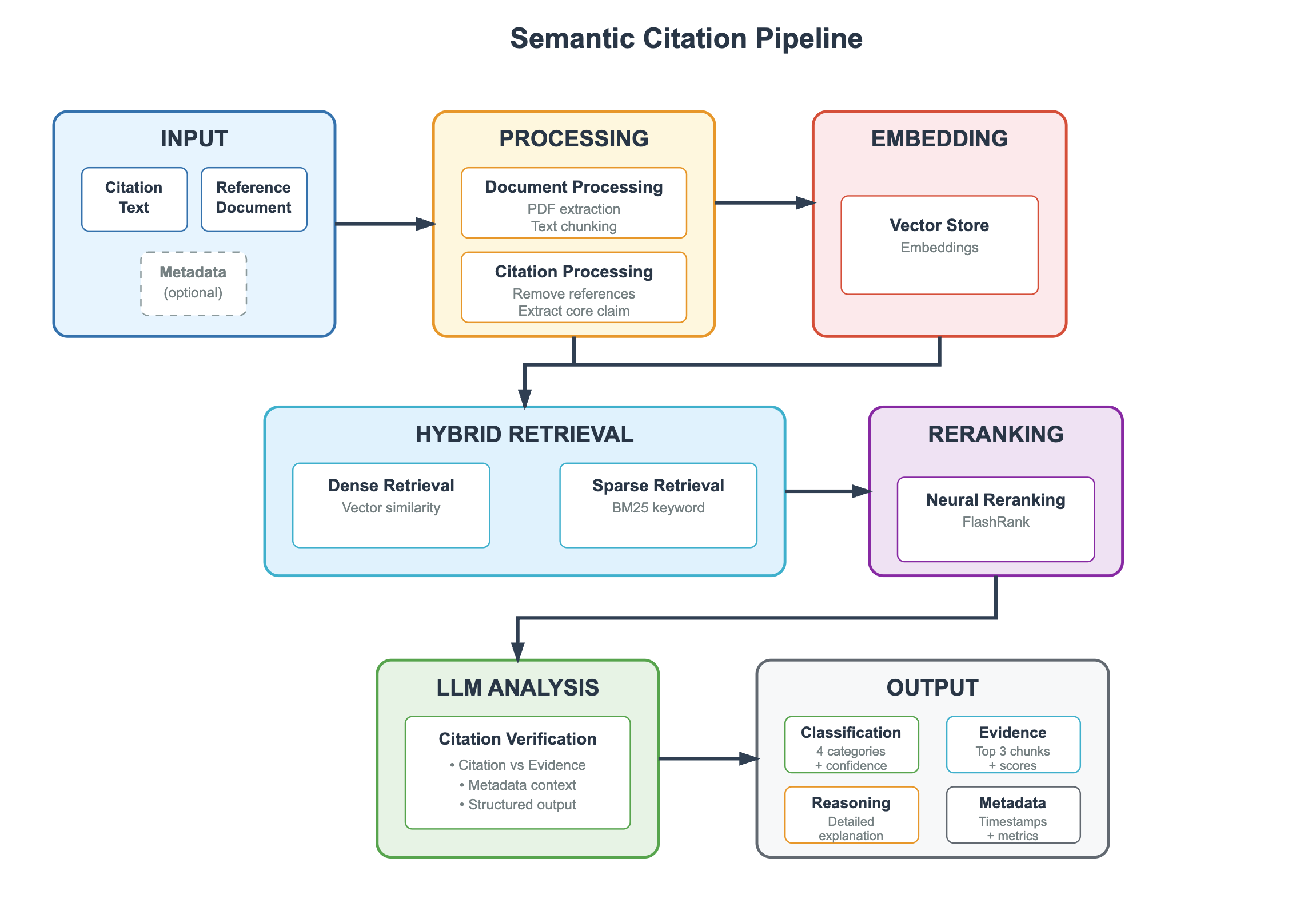
The image is a flowchart illustrating a semantic citation pipeline. It outlines the steps involved in processing citation text and reference documents to produce structured output, including classification, evidence, reasoning, and metadata. The pipeline consists of several stages: Input, Processing, Embedding, Hybrid Retrieval, Reranking, LLM Analysis, and Output.
### Components/Axes
The diagram consists of rectangular boxes representing different stages of the pipeline, connected by arrows indicating the flow of information. Each box contains a title and a brief description of the processes involved. The boxes are color-coded to visually distinguish the different stages.
* **INPUT** (Light Blue): Contains "Citation Text", "Reference Document", and "Metadata (optional)".
* **PROCESSING** (Yellow): Contains "Document Processing" (PDF extraction, Text chunking) and "Citation Processing" (Remove references, Extract core claim).
* **EMBEDDING** (Light Red): Contains "Vector Store" and "Embeddings".
* **HYBRID RETRIEVAL** (Light Blue): Contains "Dense Retrieval" (Vector similarity) and "Sparse Retrieval" (BM25 keyword).
* **RERANKING** (Purple): Contains "Neural Reranking" and "FlashRank".
* **LLM ANALYSIS** (Light Green): Contains "Citation Verification" (Citation vs Evidence, Metadata context, Structured output).
* **OUTPUT** (Light Gray): Contains "Classification" (4 categories + confidence), "Evidence" (Top 3 chunks + scores), "Reasoning" (Detailed explanation), and "Metadata" (Timestamps + metrics).
### Detailed Analysis or ### Content Details
1. **INPUT:**
* Citation Text: The text of the citation being analyzed.
* Reference Document: The document being cited.
* Metadata (optional): Additional information about the citation or document.
2. **PROCESSING:**
* Document Processing:
* PDF extraction: Extracting text from PDF documents.
* Text chunking: Dividing the text into smaller segments.
* Citation Processing:
* Remove references: Removing references from the citation text.
* Extract core claim: Identifying the main assertion made by the citation.
3. **EMBEDDING:**
* Vector Store: A database for storing vector embeddings.
* Embeddings: Numerical representations of the text.
4. **HYBRID RETRIEVAL:**
* Dense Retrieval:
* Vector similarity: Finding similar vectors.
* Sparse Retrieval:
* BM25 keyword: Using BM25 to find relevant keywords.
5. **RERANKING:**
* Neural Reranking:
* FlashRank: A neural reranking model.
6. **LLM ANALYSIS:**
* Citation Verification:
* Citation vs Evidence: Comparing the citation to the evidence.
* Metadata context: Using metadata to provide context.
* Structured output: Generating structured output.
7. **OUTPUT:**
* Classification:
* 4 categories + confidence: Classifying the citation into one of four categories, along with a confidence score.
* Evidence:
* Top 3 chunks + scores: Providing the top three chunks of evidence, along with their scores.
* Reasoning:
* Detailed explanation: Providing a detailed explanation of the reasoning behind the classification.
* Metadata:
* Timestamps + metrics: Providing timestamps and other metrics.
### Key Observations
* The pipeline starts with inputting citation text and reference documents.
* The processing stage involves document and citation processing.
* Embedding creates vector representations of the text.
* Hybrid retrieval combines dense and sparse retrieval methods.
* Reranking uses neural models to improve the ranking of results.
* LLM analysis verifies the citation and generates structured output.
* The output includes classification, evidence, reasoning, and metadata.
### Interpretation
The diagram illustrates a comprehensive pipeline for semantic citation analysis. It combines various techniques, including document processing, embedding, retrieval, reranking, and LLM analysis, to extract meaningful information from citations and generate structured output. The pipeline aims to provide a more nuanced understanding of citations by considering both the text and the context in which they appear. The use of hybrid retrieval and neural reranking suggests an effort to improve the accuracy and relevance of the results. The final output, including classification, evidence, reasoning, and metadata, provides a rich set of information that can be used for various purposes, such as citation verification, knowledge discovery, and information retrieval.