\n
## Diagram: Semantic Citation Pipeline
### Overview
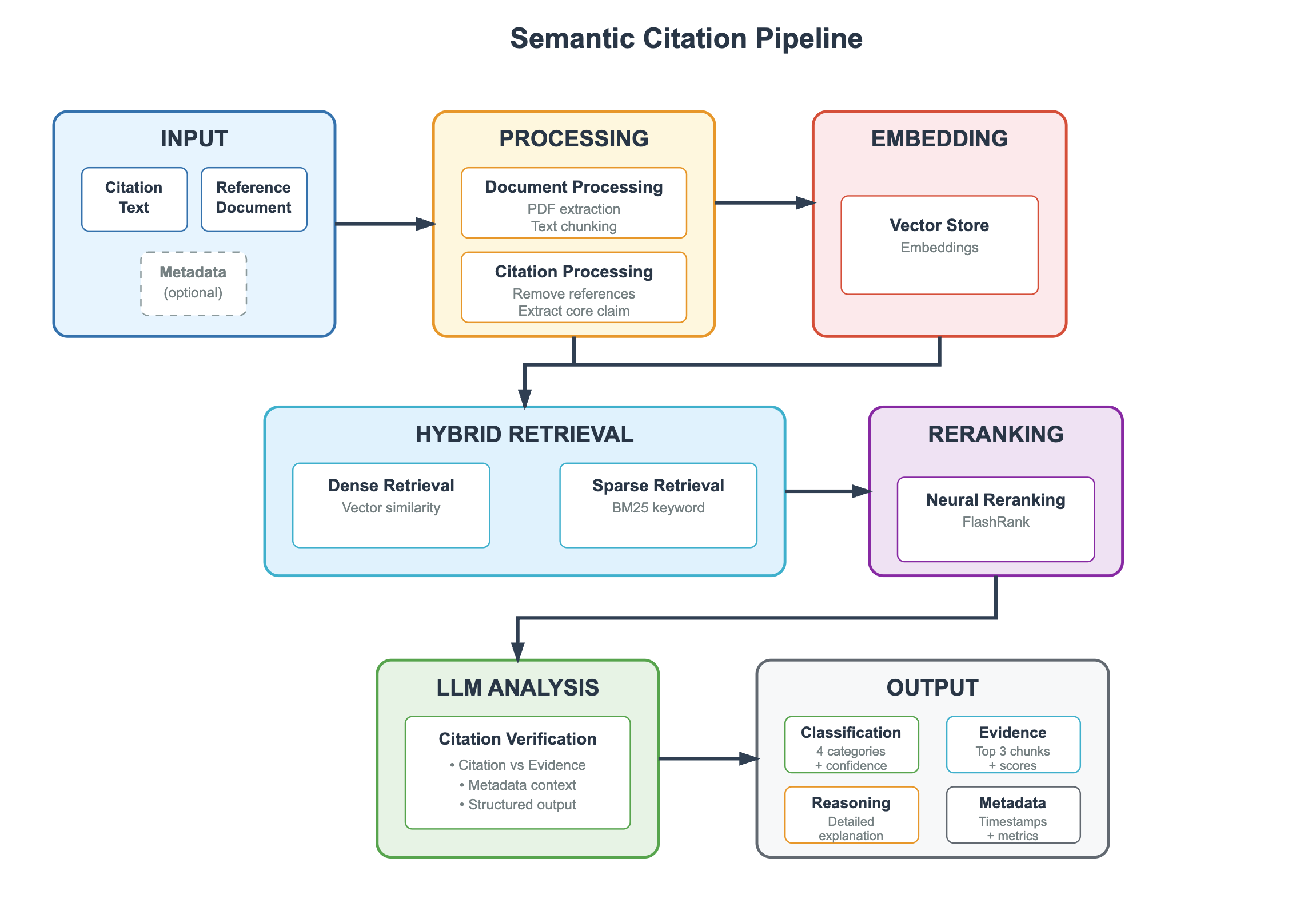
This diagram illustrates the workflow of a "Semantic Citation Pipeline," detailing the steps involved in processing citation text, retrieving relevant information, and generating structured output. The pipeline is presented as a series of interconnected boxes representing different stages, with arrows indicating the flow of data.
### Components/Axes
The diagram is divided into six main sections: INPUT, PROCESSING, EMBEDDING, HYBRID RETRIEVAL, LLM ANALYSIS, and OUTPUT. Each section contains one or more processing blocks. The diagram uses dashed lines to indicate optional inputs.
### Content Details
**INPUT:**
* Citation Text
* Reference Document
* Metadata (optional)
**PROCESSING:**
* Document Processing: PDF extraction, Text chunking
* Citation Processing: Remove references, Extract core claim
**EMBEDDING:**
* Vector Store: Embeddings
**HYBRID RETRIEVAL:**
* Dense Retrieval: Vector similarity
* Sparse Retrieval: BM25 keyword
**RERANKING:**
* Neural Reranking: FlashRank
**LLM ANALYSIS:**
* Citation Verification: Citation vs Evidence, Metadata context, Structured output
**OUTPUT:**
* Classification: 4 categories + confidence
* Evidence: Top 3 chunks + scores
* Reasoning: Detailed explanation
* Metadata: Timestamps + metrics
The diagram uses arrows to show the flow of information. The flow starts at the INPUT section, proceeds through PROCESSING, EMBEDDING, HYBRID RETRIEVAL, RERANKING, LLM ANALYSIS, and finally reaches the OUTPUT section.
### Key Observations
The pipeline emphasizes a hybrid approach to retrieval, combining dense vector similarity search with sparse BM25 keyword search. The use of an LLM for citation verification and reasoning suggests a focus on semantic understanding and accuracy. The optional metadata input indicates flexibility in the pipeline's configuration.
### Interpretation
The diagram represents a sophisticated system for analyzing citations. It moves beyond simple keyword matching to incorporate semantic understanding through vector embeddings and LLM analysis. The pipeline aims to not only retrieve relevant documents but also to verify the claims made in citations, provide evidence to support those claims, and offer a reasoned explanation. The inclusion of metadata and metrics in the output suggests a focus on traceability and evaluation. The pipeline is designed to handle both citation text and the referenced documents, allowing for a comprehensive analysis of the citation context. The optional metadata input suggests the system can be adapted to different data sources and use cases. The use of "FlashRank" for neural reranking indicates a focus on efficiency and scalability. The overall design suggests a system intended for research, knowledge discovery, or automated fact-checking.