## Diagram: Semantic Citation Pipeline
### Overview
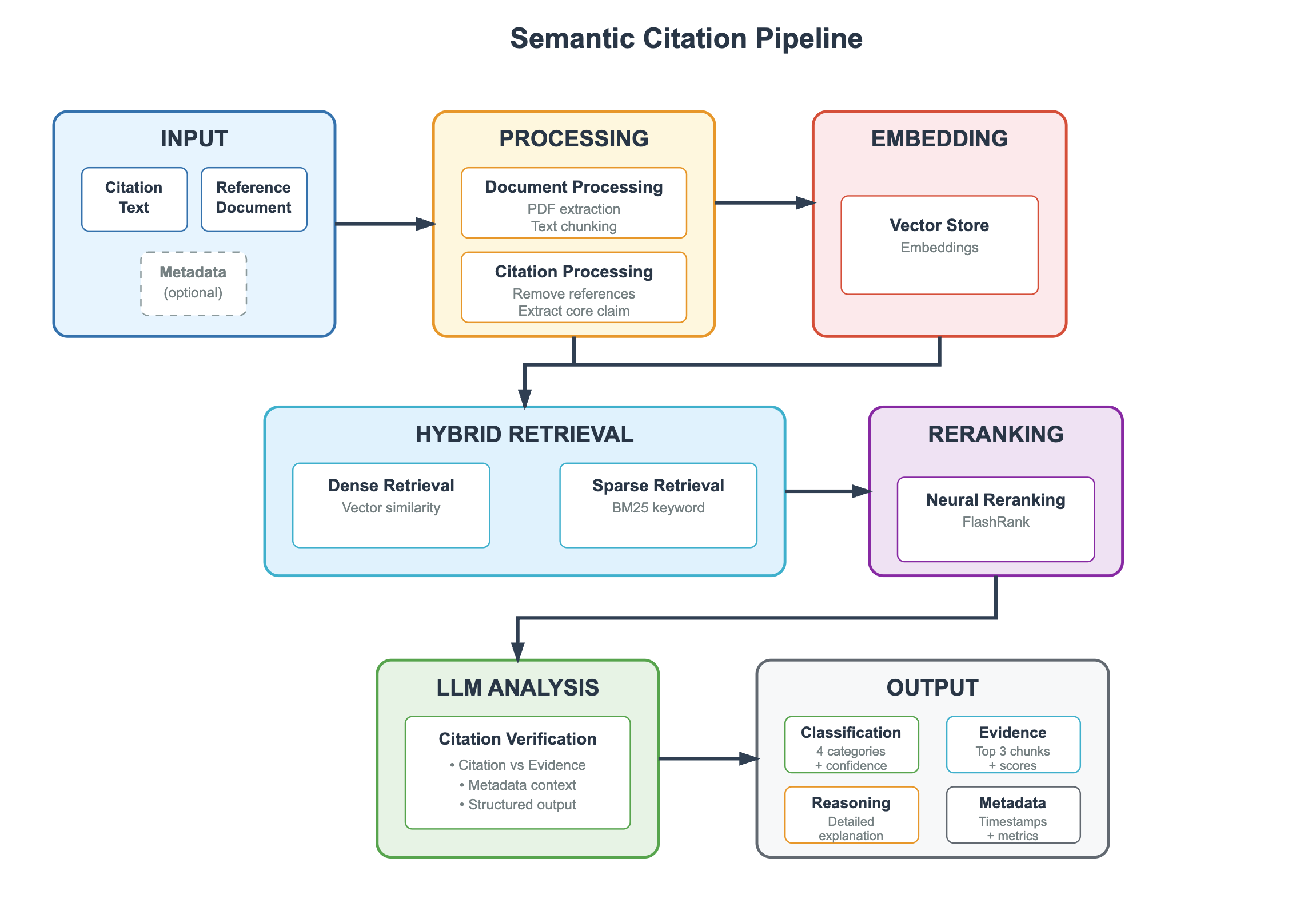
The image is a technical flowchart titled "Semantic Citation Pipeline." It illustrates a multi-stage process for verifying citations against reference documents using a combination of traditional and AI-powered methods. The pipeline flows from left to right and top to bottom, with distinct, color-coded stages connected by directional arrows indicating the sequence of operations.
### Components
The diagram is composed of seven primary, color-coded rectangular boxes representing stages, connected by dark gray arrows. Each stage contains one or more sub-components.
**1. INPUT (Top-Left, Blue Box)**
* **Citation Text** (Solid border box)
* **Reference Document** (Solid border box)
* **Metadata** (Dashed border box, labeled "optional")
**2. PROCESSING (Top-Center, Orange Box)**
* **Document Processing**
* PDF extraction
* Text chunking
* **Citation Processing**
* Remove references
* Extract core claim
**3. EMBEDDING (Top-Right, Red Box)**
* **Vector Store**
* Embeddings
**4. HYBRID RETRIEVAL (Center-Left, Light Blue Box)**
* **Dense Retrieval**
* Vector similarity
* **Sparse Retrieval**
* BM25 keyword
**5. RERANKING (Center-Right, Purple Box)**
* **Neural Reranking**
* FlashRank
**6. LLM ANALYSIS (Bottom-Left, Green Box)**
* **Citation Verification**
* Citation vs Evidence
* Metadata context
* Structured output
**7. OUTPUT (Bottom-Right, Gray Box)**
* **Classification** (Green sub-box)
* 4 categories + confidence
* **Evidence** (Blue sub-box)
* Top 3 chunks + scores
* **Reasoning** (Orange sub-box)
* Detailed explanation
* **Metadata** (Gray sub-box)
* Timestamps + metrics
### Detailed Analysis: Flow and Relationships
The pipeline's data flow is explicitly defined by the arrows:
1. The **INPUT** stage (Citation Text, Reference Document, optional Metadata) feeds directly into the **PROCESSING** stage.
2. **PROCESSING** splits into two parallel paths:
* The processed document data flows to the **EMBEDDING** stage.
* The processed citation data flows down to the **HYBRID RETRIEVAL** stage.
3. The **EMBEDDING** stage (Vector Store) also feeds its output into the **HYBRID RETRIEVAL** stage.
4. The **HYBRID RETRIEVAL** stage, combining Dense and Sparse methods, sends its results to the **RERANKING** stage.
5. The **RERANKING** stage outputs to the **LLM ANALYSIS** stage.
6. Finally, the **LLM ANALYSIS** stage produces the structured **OUTPUT**.
### Key Observations
* **Hybrid Approach:** The core retrieval mechanism is explicitly hybrid, combining semantic "Dense Retrieval" (vector similarity) with lexical "Sparse Retrieval" (BM25 keyword matching).
* **Two-Stage Ranking:** Retrieval is followed by a dedicated "Neural Reranking" step using FlashRank, indicating a focus on precision after initial candidate selection.
* **LLM as Verifier:** The Large Language Model (LLM) is positioned not as a retriever but as an analyst that performs "Citation Verification" using the retrieved evidence and context.
* **Structured, Multi-faceted Output:** The final output is not a simple yes/no but a rich, structured object containing a classification, the top evidence chunks with scores, a reasoning explanation, and operational metadata.
* **Visual Coding:** Each major stage has a unique color (blue, orange, red, light blue, purple, green, gray), aiding in visual segmentation of the process.
### Interpretation
This diagram outlines a sophisticated system designed to move beyond simple keyword matching for citation verification. It represents a **Retrieval-Augmented Generation (RAG) pipeline specialized for academic or factual citation checking**.
The process begins by ingesting a citation and its purported source document. It then processes both into a searchable format. The use of a **hybrid retrieval** strategy (dense + sparse) suggests the system aims to balance semantic understanding with precise keyword matching to find the most relevant text chunks from the reference document.
The subsequent **neural reranking** step is critical for filtering and ordering these chunks by relevance before they are passed to the LLM. This prevents the LLM from being overwhelmed with irrelevant context and improves the accuracy of the final analysis.
The **LLM's role** is specifically defined as "Citation Verification." It compares the core claim of the citation against the retrieved evidence, considers any provided metadata, and generates a structured verdict. The final **OUTPUT** is designed for both human consumption (via the "Reasoning" explanation) and programmatic use (via the "Classification," "Evidence" scores, and "Metadata").
In essence, this pipeline automates the scholarly task of checking whether a citation accurately reflects the content of its source document, providing a transparent, auditable, and multi-faceted result. It emphasizes accuracy through a multi-stage filtering process and delivers a comprehensive report rather than a binary answer.