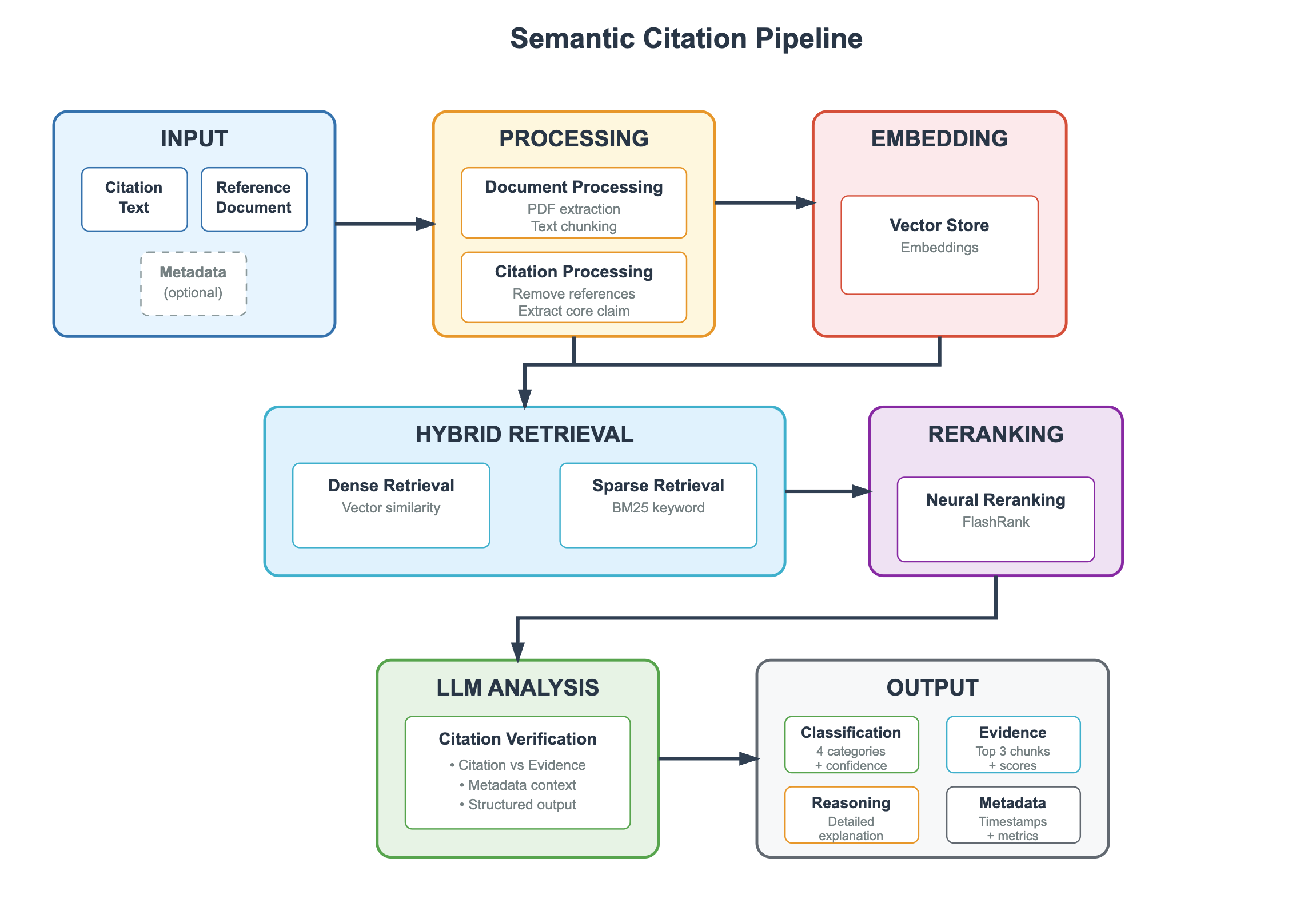
## Flowchart: Semantic Citation Pipeline
### Overview
The image depicts a multi-stage pipeline for processing citations and reference documents using a combination of traditional NLP techniques, vector embeddings, and large language model (LLM) analysis. The workflow progresses from raw input data through processing, embedding, retrieval, reranking, and finally to structured output with verification.
### Components/Axes
**Input Stage (Blue Box):**
- Citation Text
- Reference Document
- Metadata (optional)
**Processing Stage (Orange Box):**
- Document Processing
- PDF extraction
- Text chunking
- Citation Processing
- Remove references
- Extract core claim
**Embedding Stage (Red Box):**
- Vector Store (Embeddings)
**Hybrid Retrieval Stage (Light Blue Box):**
- Dense Retrieval (Vector similarity)
- Sparse Retrieval (BM25 keyword)
**Reranking Stage (Purple Box):**
- Neural Reranking (FlashRank)
**LLM Analysis Stage (Green Box):**
- Citation Verification
- Citation vs Evidence
- Metadata context
- Structured output
**Output Stage (Gray Box):**
- Classification (4 categories)
- Evidence (Top 3 chunks + scores)
- Reasoning (Detailed explanation)
- Metadata (Timestamps + metrics)
### Detailed Analysis
1. **Flow Direction**:
- Input → Processing → Embedding → Hybrid Retrieval → Reranking → LLM Analysis → Output
- Embedding branches to both Hybrid Retrieval and Reranking
- Hybrid Retrieval branches to Reranking
2. **Color Coding**:
- Blue: Input
- Orange: Processing
- Red: Embedding
- Light Blue: Hybrid Retrieval
- Purple: Reranking
- Green: LLM Analysis
- Gray: Output
3. **Key Techniques**:
- BM25 keyword retrieval
- FlashRank neural reranking
- Vector similarity matching
- 4-category classification system
### Key Observations
- The pipeline integrates both traditional (BM25) and modern (vector similarity) retrieval methods
- Metadata is used throughout the process, from input to final output
- Verification occurs at two stages: during citation processing and final LLM analysis
- The output includes both structured data (classification) and explanatory text (reasoning)
### Interpretation
This pipeline demonstrates a hybrid approach to citation verification that combines:
1. **Semantic Search**: Through vector embeddings and similarity matching
2. **Keyword Matching**: Using BM25 for sparse retrieval
3. **Neural Reranking**: To improve relevance of retrieved documents
4. **LLM Verification**: For final citation validation and explanation generation
The system appears designed to handle complex citation verification tasks by:
- First processing raw documents into structured chunks
- Creating both dense and sparse representations
- Using multiple retrieval strategies to find relevant evidence
- Finally using an LLM to verify claims against evidence and generate explanations
The presence of metadata at multiple stages suggests the system can handle temporal or contextual verification needs, while the 4-category classification implies a structured approach to categorizing citation types or verification outcomes.